Revizuirea metodelor existente de recunoaștere a modelelor. Recunoașterea modelelor Termeni și definiții ale subiectului recunoașterii modelelor
În ultimul deceniu, a existat un interes semnificativ în cercetarea și construcția sistemelor de recunoaștere automată a modelelor și învățare automată. Am asistat la progrese rapide în acest domeniu. Exemplele de sisteme de recunoaștere automată a modelelor abundă. Au fost făcute încercări cu succes de a crea dispozitive și programe pentru citirea caracterelor tipografice și dactilografiate, procesarea electrocardiogramelor și electroencefalogramelor, recunoașterea cuvintelor rostite, identificarea amprentelor digitale și interpretarea fotografiilor. Alte aplicații includ recunoașterea caracterelor și a cuvintelor scrise de mână, diagnosticarea medicală, clasificarea undelor seismice, detectarea obiectelor inamice, prognoza meteo, identificarea defecțiunilor și a defecțiunilor mecanismelor individuale și a întregului proces de producție. În această secțiune, luăm în considerare câteva exemple ilustrative legate de acele domenii în care principiile recunoașterii modelelor și-au găsit aplicarea cu succes.
Recunoașterea caracterelor
Un exemplu de utilizare practică a clasificării automate a modelelor sunt dispozitivele optice de recunoaștere a caracterelor, în special mașinile pentru citirea caracterelor codurilor din cecurile bancare obișnuite.
Orez. 1.7. (vezi scanarea) Setul de fonturi E-13B al Asociației Bancherilor Americani și formele de undă corespunzătoare caracterelor individuale ale setului.
Majoritatea cecurilor aflate în circulație în prezent în Statele Unite folosesc fontul standard E-13B al Asociației Bancherilor Americani ca caractere stilizate. După cum rezultă din Fig. 1.7, acest set include 14 simboluri special adaptate zonelor care contine retina pentru a simplifica procesul de citire. Aceste caractere sunt de obicei aplicate cu o cerneală specială de imprimare care conține foarte
material magnetic măcinat fin. Dacă caracterele sunt citite cu ajutorul unui dispozitiv magnetic, cerneala este premagnetizată pentru a separa caracterele de fundal și a facilita astfel procesul de citire.
Caracterele sunt de obicei scanate orizontal cu un cap de citire prevăzut cu un singur slot mai îngust și mai înalt decât un singur caracter. La traversarea unui simbol, capul generează un semnal electric, a cărui mărime este proporțională cu rata de creștere a spațiului ocupat de simbol sub capul de scanare. Luați în considerare, ca exemplu, semnalul corespunzător numărului „0” (Fig. 1.7). Pe măsură ce capul citit se mișcă de la stânga la dreapta, zona caracterului pe care o vede capul începe să crească, rezultând o derivată pozitivă. Pe măsură ce capul începe să părăsească „rack-ul” din stânga zero, aria cifrei din câmpul vizual al capului începe să scadă, dând o derivată negativă. Când capul se află în zona de mijloc a simbolului, aria rămâne constantă, iar derivata este în mod corespunzător zero. Acest model se repetă atunci când coroana ajunge la stâlpul din dreapta, așa cum se arată în figură. Vedem că forma simbolurilor este aleasă în așa fel încât semnalele corespunzătoare diferitelor simboluri să difere în mod clar unele de altele. Trebuie remarcat faptul că punctele extreme și zerourile fiecărui semnal apar aproape exact pe generatoarele verticale ale grilei folosite ca fundal pentru afișarea semnalelor. Forma caracterelor din fontul E-13B a fost aleasă în așa fel încât eșantionarea valorilor semnalului doar în aceste puncte să fie suficientă pentru clasificarea lor corectă. Memoria cititorului pentru fiecare dintre cele 14 caractere ale fontului conține valori corespunzătoare doar acestor puncte. Când un simbol intră în clasificare, sistemul compară semnalul corespunzător acestuia cu standardele de semnal introduse anterior în memorie și îl atribuie clasei standardului cel mai asemănător cu acesta. Cu o astfel de schemă de clasificare, ar trebui utilizat fie principiul enumerarii membrilor clasei, fie principiul comunității proprietăților. Cele mai multe dispozitive moderne concepute pentru a citi fonturi stilizate funcționează într-un mod similar.
Există și versiuni comerciale ale cititoarelor de fonturi. tipuri diferite. Astfel, de exemplu, sistemul Input 80 (Fig. 1.8), dezvoltat de Recognition Equipment Incorporated, poate citi informațiile prezentate sub formă dactilografică, tipografică și scrisă de mână direct din documentele originale cu o viteză de până la
3600 de caractere pe secundă. Dicționarul de sistem este construit pe un principiu modular și poate fi reconstruit pe baza cerințelor unei aplicații specifice. Un singur sistem de fonturi este capabil să citească caractere dintr-unul dintre multele seturi de fonturi binecunoscute, iar un sistem cu mai multe fonturi vă permite să lucrați „simultan” cu un număr de tipuri de fonturi selectate de utilizator dintr-o varietate de fonturi valide. Un dispozitiv poate recunoaște până la 360 de caractere diferite. Sistemul poate fi configurat, de asemenea, să citească numere dactilografiate, să selecteze litere și simboluri dactilografiate și să citească date tipărite.
Orez. 1.8. (vezi scanarea) Sistemul de recunoaștere a caracterelor REI Input 80 Model A de la Recognition Equipment Incorporated, Dallas, Texas. Figura prezintă următoarele componente ale sistemului (în sensul acelor de ceasornic): unitate de recunoaștere, controler controlat de program, imprimantă de intrare/ieșire a datelor, imprimantă de linie, unitate de recunoaștere, unitate de bandă magnetică și procesor de pagini. Fotografie oferită de Recognition Equipment Incorporated.
Principalele caracteristici ale sistemului REI „Input 80” sunt următoarele. Paginile sunt alimentate printr-un sistem de secțiuni rare și ejectoare de aer pe o bandă transportoare, care le alimentează într-un cititor. Aici, o oglindă oscilantă de înaltă frecvență concentrează un fascicul de lumină de mare intensitate asupra caracterelor de citit; fasciculul traversează șirul de caractere tipărite cu o viteză de aproximativ 7,62 m/s. Cea de-a doua oglindă, sincronizată, percepe imagini luminoase reprezentând
diverse părți ale simbolului și le proiectează pe o „retină integrată” - un cititor realizat pe un circuit integrat; este format din 96 de fotodiode adăpostite într-o singură placă de siliciu cu lungimea de aproximativ 38,1 mm. Acest dispozitiv este „ochiul” sistemului. Retina integrată codifică fiecare caracter, reprezentându-l folosind o matrice de 16X12 celule, standardizează caracterele, le corectează în funcție de variațiile de dimensiune ale acestora, funcționând cu o viteză de până la 3600 de caractere pe secundă. Retina integrală, în plus, clasifică fiecare celulă a reprezentării fiecărui simbol în conformitate cu apartenența la unul dintre cele 16 niveluri de întuneric.
Datele de la ieșirea cititorului sunt transmise la unitatea de recunoaștere, în care nivelurile de întuneric ale tuturor celulelor imaginii caracterului sunt comparate cu nivelurile de întuneric ale a 24 de celule învecinate; pentru aceasta se folosește o schemă adecvată de amplificare a semnalului video. Datele obținute în urma acestei operațiuni sunt cuantificate, ceea ce duce la o imagine alb-negru de un bit. Acest proces vă permite să neteziți imaginea personajului, să saturați liniile subtile, să eliminați petele și să creșteți contrastul cu un fundal zgomotos. Sistemul recunoaște caracterele tastate tipografic căutând cea mai mică discrepanță între caracterul citit și caracterele incluse în dicționarul unității de recunoaștere. De asemenea, sistemul se asigură că nepotrivirea minimă găsită diferă într-o cantitate suficientă de cea mai apropiată nepotrivire cu un alt simbol de dicționar. Metoda adecvată de implementare a clasificării va fi discutată în Cap. 3.
Recunoașterea caracterelor dactilografiate se realizează folosind o procedură logică de alt tip. Caracterele dactilografiate nu se potrivesc cu imaginile pre-memorate, ci sunt analizate din punct de vedere al prezenței anumitor caracteristici comune, cum ar fi linii curbe, orizontale și verticale, unghiuri și intersecții. În acest caz, clasificarea unui simbol se realizează pe baza detectării anumitor caracteristici din acesta, precum și a relațiilor lor. Blocurile sistemului de recunoaștere a caracterelor sunt prezentate în fig. 1.8, numele lor sunt date în legenda de sub figură.
Clasificarea automată a datelor primite de la distanță
Interesul relativ recent din Statele Unite pentru calitatea mediului și resurse naturale a dat naștere la numeroase aplicații ale metodelor
recunoasterea formelor. Cea mai mare atenție dintre ele este atrasă de clasificarea automată a datelor primite de la distanță. Deoarece volumul de date obținut de la dispozitivele de scanare spectrală multi-bandă instalate pe aeronave, sateliți și stații spațiale este extrem de mare, a devenit necesar să se apeleze la mijloace automate de procesare și analiză a acestor informații. Colectarea datelor de la distanță este utilizată în rezolvarea diferitelor probleme. Domeniile de interes curent includ utilizarea terenurilor, evaluarea culturilor, detectarea bolilor culturilor, silvicultură, controlul calității aerului și apei, studii geologice și geografice, prognoza meteo și o serie de alte probleme de mediu.
Ca exemplu de clasificare automată a rezultatelor unui studiu spectral, luați în considerare Fig. 1.9, a, care prezintă o fotografie color a suprafeței pământului luată de la o aeronavă. Imaginea reprezintă o zonă mică de-a lungul traseului de zbor (mai multe mile) situată în regiunea centrală a Indianei. Scopul este de a colecta suficiente date pentru a antrena mașina să recunoască automat tipuri variate acoperirea solului (clasele), cum ar fi solul deschis sau întunecat, apa de râu sau iaz și stadiile de maturare a vegetației verzi.
Un dispozitiv de scanare multibandă răspunde la lumină cu benzi de lungime de undă specifice. Dispozitivul de scanare utilizat în zborul menționat funcționează în benzi de lungimi de undă de microni. Aceste intervale se referă la regiunile violet, verde, roșu și, respectiv, infraroșu. Utilizarea acestei metode duce la patru imagini pentru o zonă a suprafeței pământului - una pentru fiecare zonă de culoare. Prin urmare, fiecare punct al complotului este caracterizat de patru componente reprezentând o culoare. Informațiile pentru fiecare punct pot fi reprezentate printr-un vector imagine cu patru dimensiuni, unde este nuanța de violet, este nuanța de verde etc. Setul de imagini aparținând unei anumite clase de strat de sol constituie setul de antrenament pentru această clasă. Aceste imagini de antrenament pot fi apoi folosite pentru a construi un clasificator.
Pe baza datelor spectrale obținute în timpul zborului considerat, a fost construit un clasificator bayesian pentru modele care se supun unei distribuții normale (vezi § 4.3). Pe fig. 1.9, b arată rezultatul rezultat al mașinii

utilizarea unui astfel de clasificator pentru clasificarea automată a datelor spectrale myo-o-band corespunzătoare unei zone mici a suprafeței pământului, prezentată în Fig. 1.9, a. Săgețile indică unele caracteristici de interes deosebit. Săgeata 1 este plasată în colțul câmpului de vegetație verde, săgeata 2 indică râul. Săgeata 3 marchează un mic gard viu care separă două petice de sol gol; aceste obiecte sunt identificate clar pe tipărit. Afluentul, care este și el identificat corect, este marcat cu săgeata 4. Săgeata 5 indică un iaz foarte mic, care este aproape imposibil de distins în fotografia color. Când comparăm imaginea originală cu rezultatele clasificării mașinii, devine evident că acestea din urmă corespund foarte strâns concluziilor la care ar ajunge o persoană prin interpretarea vizuală a fotografiei originale.
Aplicații biomedicale
După cum sa menționat în § 1.1, medicina se confruntă în prezent cu probleme serioase legate de prelucrarea informațiilor. Metodele de recunoaștere a modelelor au fost folosite cu diferite grade de succes pentru a procesa automat datele obținute folosind diverse instrumente tehnice utilizate în diagnosticarea medicală, cum ar fi radiografii, electrocardiograme, electroencefalograme și pentru a analiza și interpreta chestionarele pacientului. Una dintre sarcinile care a primit multă atenție este automatizarea analizei și clasificării cromozomilor.
Interesul pentru automatizarea analizei cromozomilor este cauzat de faptul că automatizarea analizei citogenetice va extinde posibilitățile de utilizare a studiilor cromozomiale în diagnosticul clinic. În plus, va permite studii de populație preventive la scară largă pentru a evalua impactul patologic al unui număr de mici variații ale modelului cromozomial, al căror impact este în prezent necunoscut. În plus, capacitatea de a examina grupuri mari ale populației va face posibilă efectuarea unui număr de alte studii medicale valoroase, de exemplu, o examinare citogenetică generală a fătului înainte de naștere și a nou-născuților pentru a determina necesitatea unui tratament preventiv sau terapeutic. expunere, screening-ul unor grupuri individuale de persoane identificate prin factori de afiliere profesională sau de rezidență într-o anumită zonă și caracterizate de aberații cromozomiale crescute cauzate de un efect dăunător sau testarea de noi
Orez. 1.10. (Vezi scanarea) Celule sanguine umane, colorate cu colorant Giemsa, un preparat care demonstrează structura cromozomilor. Ilustrație prin amabilitatea Dr. Niel Wald, Școala Absolventă de Sănătate Publică, Universitatea din Pittsburgh, Universitatea din Pittsburgh.
substanțe chimice și medicamente în ceea ce privește potențialul pericol pentru cromozomi.
Pe fig. 1.10 prezintă un preparat tipic preparat din celule sanguine umane în metafaza mitozei și colorat conform Giemsa. Cea mai obositoare și îndelungată parte a analizei unei astfel de imagini este asociată cu procesul de codificare - un medic sau un asistent de laborator calificat
trebuie să clasifice fiecare cromozom separat. Figura prezintă obiecte aparținând unor grupuri tipice de clasificare,
Au fost propuse multe metode de clasificare automată a cromozomilor. Una dintre abordările care s-au dovedit a fi eficace în clasificarea tipurilor de cromozomi prezentate în Fig. 1.10 se bazează pe principiul recunoașterii modelelor sintactice discutat în Cap. 8. Esența acestei abordări este următoarea. Se disting elemente nederivate ale imaginii, cum ar fi arce lungi, arcuri scurte și segmente semidrepte, care denotă limitele cromozomului. Combinarea unor astfel de elemente și elemente derivate duce la lanțuri sau propoziții alcătuite din unele simboluri; acesta din urmă poate fi pus în conformitate cu așa-numita gramatică a imaginilor. Fiecare tip (clasă) de cromozomi are propria sa gramatică. Pentru a identifica un anumit cromozom, un computer își urmărește limitele și generează un lanț format din elemente nederivate. Baza algoritmului de urmărire este de obicei o procedură euristică care vă permite să rezolvați dificultățile asociate cu adiacența și suprapunerea cromozomilor. Lanțul astfel obținut este introdus în sistemul de recunoaștere, care determină dacă este o propoziție corectă, compusă din simboluri după regulile unor gramatici. Dacă acest proces are ca rezultat specificarea unei anumite gramatici, cromozomul este atribuit clasei corespunzătoare acelei gramatici. Dacă un astfel de proces nu permite obținerea unei interpretări clare sau eșuează deloc, funcționarea sistemului cu acest cromozom este încheiată și analizele suplimentare sunt efectuate de către operator.
Deși nu a fost găsită o soluție generală la problema recunoașterii automate a cromozomilor, sistemele moderne de recunoaștere care utilizează o abordare sintactică reprezintă un pas important în direcția corectă. În § 8.5 vom reveni la acest tipar de recunoaștere și vom analiza în detaliu gramatica cromozomială corespunzătoare.
Recunoașterea amprentei
După cum am menționat în § 1.1, agențiile guvernamentale au arhive care conțin peste 200 de milioane de amprente. Divizia de identificare a Biroului Federal de Investigații are, în special, cea mai mare arhivă de amprente din lume - peste 160 de milioane. Departamentul primește zilnic până la 30.000 de întrebări. Pentru a face față acestei cantități de muncă,
aproximativ 1.400 de tehnicieni și oficiali trebuie să clasifice cu atenție imprimeurile noi și apoi să caute cu meticulozitate meciurile.
De câțiva ani, FBI și-a arătat interesul pentru dezvoltarea unui sistem automat de identificare a amprentelor. Un exemplu de eforturi în această direcție este sistemul prototip FINDER dezvoltat de Calspan Corporation în numele FBI. Acest sistem detectează și localizează automat caracteristicile caracteristice imprimării. Caracteristicile pe care sistemul le detectează nu sunt elemente structurale mari precum arce, contururi sau bucle utilizate în procesul de clasificare primară a imprimeurilor, ci mai degrabă detalii mici - capetele și ramificațiile canelurilor, similare cu cele prezentate în Fig. 1.11.

Orez. 1.11. Fragmente - capetele canelurilor (pătratelor) și furcilor (cercurilor) - utilizate de sistemul FINDER la identificarea amprentelor digitale. Fotografie prin amabilitatea domnului C. W. Swanger de la Calspan Corporation, Buffalo, NY.
Pe fig. 1.12 prezintă o diagramă bloc a sistemului. Pe scurt, funcționarea sistemului FINDER poate fi descrisă după cum urmează. Operatorul introduce un semifabricat standard de imprimare în dispozitivul de introducere automată, care livrează imprimarea către „ochiul” sistemului - dispozitivul de scanare și plasează cu precizie imprimarea sub acesta. Fiecare tipărire este cuantificată și reprezentată printr-o matrice care conține 750X750 de puncte, fiecare punct fiind codificat cu unul dintre cele 16 niveluri posibile de întuneric. Procesul de scanare se desfășoară sub controlul unui computer universal. Pe fig. 1.13 este un exemplu care arată ce formă ia o imprimare după ce trece printr-un dispozitiv de împrăștiere.
Datele obținute la ieșirea dispozitivului de împrăștiere sunt introduse în filtrul groove-groove, care este implementat folosind un algoritm de mare viteză pentru procesarea paralelă a obiectelor bidimensionale; acest algoritm examinează secvenţial toate punctele matricei 750X750. Ieșirea filtrului reproduce o imagine binară îmbunătățită de tipul prezentat în Fig. 1.14. Același algoritm fixează direcția șanțurilor în fiecare punct al amprentei; aceste informații sunt utilizate în procesarea ulterioară.

(click pentru a vizualiza scanarea)
La procesarea majorității imprimărilor, în unele zone nu este posibilă izolarea unei structuri suficient de clare a canelurilor, ceea ce face posibilă detectarea în mod fiabil a fragmentelor. Dispozitivul de pre-editare exclude astfel de zone de la analiza ulterioară ca surse de informații fiabile. Testele pentru alb, întuneric, lipsă de striuri sau contrast sunt utilizate pentru a asigura detectarea fiabilă a fragmentelor.

Orez. 1.13. Imprimare a zonei obținute la ieșirea dispozitivului de scanare. În această imagine digitală, elementele negre sunt reprezentate de numărul „0”, iar elementele albe sunt reprezentate de „15”. Ilustrație prin amabilitatea dl.
C. W. Swanger de la Calspan Corporation, Buffalo, New York.
Următoarea etapă a procesării amprentei este dedicată selecției practice a fragmentelor. Acest proces este implementat folosind un algoritm sincronizat cu ieșirea filtrului groove. Selectează fragmente care sunt probabil trăsături caracteristice și înregistrează poziția lor și mărimea unghiurilor corespunzătoare.
Rezultatele blocului de selecție a fragmentelor sunt introduse în blocul de editare final. În primul rând, aria și perimetrul fragmentului selectat sunt comparate cu valorile de prag corespunzătoare caracteristicilor adevărate, ceea ce face posibilă excluderea datelor incorecte cu bună știință. În continuare, funcțiile duplicat sunt excluse. Dacă orice fragment privat este găsit de mai multe ori, atunci doar cel găsit este salvat.
lungimea cea mai mare. Utilizarea unei proceduri în lanț, în care obiectul de căutare este doar fragmente adiacente celor selectate, reduce semnificativ timpul de procesare. Apoi, îndepărtarea fragmentelor și fragmentelor care se exclud reciproc, al căror aspect este asociat cu goluri în structura canelurilor. După aceea, lista de caracteristici este liberă de fragmente a căror formă și calitate sunt sub un anumit prag.

Orez. 1.14. Rezultatele omiterii datelor prezentate în Fig. 1.13, prin filtrul canelură-canelură. În acest caz, punctele negre sunt reprezentate de simbolurile „g”. Ilustrație prin amabilitatea domnului C. W. Swanger de la Calspan Corporation, Buffalo, NY.
În ultima etapă a procesului final de editare, se determină dacă caracteristica aparține grupului de caracteristici sau unghiul corespunzător diferă semnificativ de orientarea locală a structurii canelurii. Testul cluster exclude din considerare un grup de semne de acest tip, cum ar fi cele care au apărut din cauza unei cicatrici pe un deget. Dacă se găsesc semne lângă caracteristica analizată, al cărei număr depășește o anumită valoare, această caracteristică este exclusă din analiza ulterioară ca fiind falsă. Dacă caracteristica trece ultimul test, atunci partea logică a sistemului trece la implementarea testului pentru anomalia unghiului, folosind setul de date (matricea) despre direcția canelurilor colectate.
în timpul preprocesării. În funcție de mărimea abaterii de la unghiul mediu al canelurii, semnul este lăsat, respins sau, dacă abaterea este mică, unghiul este corectat în funcție de valoarea medie a unghiurilor canelurilor adiacente.
În sfârșit, aproximativ 2500 de biți de date reprezentând caracteristicile care au trecut toate testele oferite de unitatea finală de editare sunt înregistrate pe bandă magnetică pentru a putea fi comparate cu caracteristicile tipăritelor din arhivă.
Aplicarea metodelor de recunoaștere a modelelor în supravegherea tehnică a stării unităților de reactoare nucleare
Acest ultim exemplu aparține unui domeniu relativ nou de aplicare a principiilor recunoașterii modelelor. Numeroși senzori sunt incluși în schemele instalațiilor nucleare pentru a asigura controlul asupra integrității funcționării instalației. În special, în domeniul echipamentelor de control și măsurare, înregistratorul de neutroni a devenit larg răspândit. Acest dispozitiv, conceput pentru a măsura densitatea neutronilor, generează un semnal care depinde și de vibrațiile mecanice care apar în reactor. Unul dintre scopurile principale ale utilizării acestui înregistrator într-un reactor nuclear este de a detecta cât mai devreme posibil orice moduri de oscilații interne care nu sunt caracteristice condițiilor normale de funcționare ale reactorului.
În prezent, în domeniul analizei zgomotului (neutron, acustic, termic etc.), cel mai mare interes îl reprezintă realizarea unor astfel de sisteme tehnice de control care să asigure monitorizarea modului de funcționare al instalației în ansamblu, să fie cel puțin parțial automatizate. și au capacitatea de a se adapta la schimbările de mod.nu sunt asociate cu o abatere de la normă. Sistemele de control reproduc informatii in volume uriase, care, pentru a fi utile, trebuie prelucrate prin intermediul unor procedee sistematice. Deși acest lucru nu prezintă nicio dificultate reală în acest moment, deoarece nu existau mai mult de 50 de centrale nucleare care funcționau în Statele Unite la momentul scrierii acestui articol, Comisia pentru Energie Atomică estimează că până în anul 2000, numărul de astfel de centrale. singur în Statele Unite va depăși 1 000. Desigur, va fi necesară crearea unor metode de prelucrare automată a informațiilor reproduse de numeroase sisteme de control care vor face parte din astfel de centrale nucleare.
instalatii. Deși recunoașterea în acest domeniu abia începe să facă primii pași, potențialitățile sale au fost deja pe deplin definite. Mai jos descriem pe scurt principalele rezultate obținute în această direcție.

Orez. 1.15 Componentele principale ale unui sistem automat de analiză a zgomotului.
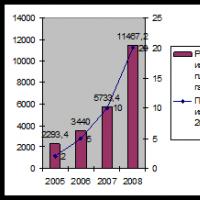
Pe fig. 1.15 prezintă principalele componente ale sistemului de control automat. Semnalele reprezentative de zgomot provenite de la senzorii instalați într-o centrală nucleară sunt normalizate, preprocesate și introduse în sistemul de recunoaștere a modelelor. La iesirea acestui sistem se reproduce o solutie care caracterizeaza starea curenta a instalatiei. În cazul nostru, vorbim despre un reactor nuclear cu o densitate mare de flux de neutroni, conceput pentru producerea de izotopi: reactorul este instalat la Laboratorul Național Oak Ridge (Laboratorul Național Oak Ridge). Rezultatele măsurătorilor zgomotului neutronic, care sunt efectuate în medie de trei ori pe zi, sunt folosite ca date inițiale pentru monitorizarea regimului acestui reactor. Ciclul de combustibil (timpul dintre reîncărcările celulei de combustibil) este de obicei de 22 de zile când funcționează la putere maximă. Pe baza acestor date, unitatea de preprocesare determină densitatea spectrală de putere în intervalul de frecvență de la 0 la 31 Hz cu un interval de 1 Hz. Prin urmare, rezultatele fiecărei măsurători pot fi reprezentate printr-un vector imagine cu 32 de dimensiuni, unde este amplitudinea densității de putere spectrală a radiației la o frecvență de 0 Hz, este amplitudinea la o frecvență de 1 Hz etc. Sarcina în acest caz este de a construi un sistem de recunoaștere a modelelor capabil să analizeze automat imagini similare.
Datele pentru două cicluri de combustibil ale unui reactor izotop cu o densitate mare de flux de neutroni sunt prezentate într-un sistem de coordonate tridimensional în Fig. 3. 1.16, a și b. Axa caracterizează timpul ciclului combustibilului, axa y reprezintă 32 de componente
fiecare imagine, iar axa z este amplitudinea normalizată a densității spectrale de putere. Datele furnizate sunt pentru funcționare normală. Rețineți că ambele grupuri de date sunt în general foarte asemănătoare.

Orez. 1.16. Densități spectrale tipice de putere a neutronilor corespunzătoare funcționării normale a unui reactor nuclear cu o densitate mare a fluxului de neutroni conceput pentru producerea de izotopi. Cele mai mari vârfuri din fiecare dintre grafice corespund unei valori de 1. Valorile adevărate ale densității spectrale pot fi obținute prin înmulțirea valorilor obținute din grafic cu factorii de scalare corespunzători. Sunt egali: . Grafice adaptate după Gonzalez, Fry și Kreiter, IEEE Trans. Nucl. Sc., 21, nr. 1, februarie 1974 (R. C. Gonzales, D. N. Fry, R. C. Kryter, Results in the Application of Pattern Recognition Methods to Nuclear Reactor Core Component Surveillance).
Un sistem de recunoaștere conceput pentru a controla modul unui reactor izotop cu extrase cu densitate mare de flux de neutroni caracteristici modului normal de funcționare din înregistrările de zgomot neutronic supuse unei procesări adecvate. Această procedură se rezumă la găsirea de clustere de vectori de imagine prin aplicarea succesivă a unui algoritm de clustering (metodele corespunzătoare sunt discutate în Capitolul 3). Datele care caracterizează poziția centrelor clusterelor, precum și statisticile descriptive de tip împrăștiere corespunzătoare pentru clusterele individuale, pot fi apoi utilizate ca repere pentru comparare la orice moment dat cu rezultatele măsurătorilor pentru a identifica curentul. starea instalatiei. Abateri semnificative de la caracteristicile specificate
în timpul funcționării normale servesc ca indicatori ai apariției unui proces anormal. Pe fig. 1.17, a și b, de exemplu, arată comportamentul reactorului, care poate fi ușor clasificat ca fiind net diferit de modul normal de funcționare. Datele date corespund cazului de defectare a lagărului de ghidare a uneia dintre unitățile mecanice situate în apropierea miezului reactorului. Deși abaterile identificate nu creează o situație care să prezinte un pericol imediat, astfel de rezultate demonstrează importanța potențială a utilizării metodelor de recunoaștere a modelelor ca parte integrantă a unui sistem de măsuri care asigură supravegherea tehnică a stării unei centrale nucleare. Detalii suplimentare referitoare la această problemă pot fi adunate din articolul lui Gonzalez, Fry și Kreiter.

Orez. 1.17. Densități spectrale corespunzătoare comportamentului anormal al unui reactor nuclear cu o densitate mare de flux de neutroni conceput pentru a produce izotopi. Factorii de scară în acest caz sunt: . Grafice adaptate după Gonzalez, Fry și Kreiter, IEEE Trans. Nucl. Sc., 21, nr. 1, februarie 1974 (R. C. Gonzalez, D. N. Fry, R. C. Kryter, Results in the Application of Pattern Recognition Methods to Nuclear Reactor Core Component Surveillance).

Roboții moderni echipați cu sisteme de viziune sunt capabili să vadă bine pentru a lucra cu lumea reală. Ei pot concluziona ce tip de obiecte sunt prezente, în ce relație sunt între ele, ce grupuri formează.
Esența problemei de recunoaștere este de a stabili dacă obiectele studiate au un set finit fix de caracteristici care le permite să fie atribuite unei anumite clase.
Obiectivele științei recunoașterii modelelor:
Înlocuirea unui expert sau complex uman sistem expert un sistem mai simplu (automatizarea activității umane sau simplificarea sistemelor complexe);
Construirea de sisteme de învățare care sunt capabile să ia decizii fără a specifica reguli clare, și anume, sisteme care sunt capabile să sintetizeze regulile de luare a deciziilor pe baza unui număr finit de exemple de decizii corecte „demonstrate” sistemului.
Sarcini de recunoaștere poate fi caracterizat astfel.
1. Acestea sunt sarcini informaționale, constând din două etape principale: aducerea datelor sursă într-o formă convenabilă pentru recunoaștere și recunoaștere în sine.
2. În aceste probleme, se poate introduce conceptul de analogie și asemănare a obiectelor și se poate formula conceptul de proximitate a obiectelor ca bază pentru atribuirea unui obiect unei anumite clase.
3. În aceste sarcini se poate opera cu un set de exemple a căror clasificare este cunoscută și care, sub formă de descrieri formalizate, pot fi prezentate algoritmului de recunoaștere pentru ajustarea la sarcina în procesul de învățare.
4. Pentru aceste probleme este dificil să construiești teorii formale și să aplici metodele matematice clasice.
5. În aceste sarcini, sunt posibile informații „proaste”.
Tipuri de sarcini de recunoaștere:
Atribuirea obiectului prezentat uneia dintre clase (instruire cu profesor);
Clasificare automată - împărțirea unui set de obiecte (situații) în funcție de descrierea acestora într-un sistem de clase care nu se suprapun;
Selectarea unui set de caracteristici informaționale pentru recunoaștere;
Aducerea datelor sursă într-o formă convenabilă pentru recunoaștere;
Recunoaștere dinamică și clasificare dinamică;
Sarcini de prognoză.
Definiții de bază
Imagine este o descriere structurată a unui obiect sau fenomen, reprezentată de un vector de trăsături, fiecare element al căruia reprezintă valoarea numerică a uneia dintre trăsăturile care caracterizează obiectul dat. Cu alte cuvinte: o imagine este orice obiect pentru care se poate măsura un set de anumite caracteristici numerice. Un exemplu de imagine: o scrisoare, o imagine, o cardiogramă etc.
Semn numeric(sau doar un semn). este o formulă sau o altă descriere a unei metode de potrivire a unui obiect cu o anumită caracteristică numerică, care operează în cadrul unei probleme specifice de recunoaștere a modelelor. Pentru fiecare obiect pot fi definite mai multe caracteristici diferite, adică mai multe caracteristici numerice.
caracteristică spațiu.Spațiu N-dimensional definit pentru o anumită sarcină de recunoaștere, unde N este un număr fix de caracteristici măsurate pentru orice obiect. Vectorul din spațiul caracteristică corespunzător obiectului problemei de recunoaștere este un vector N-dimensional cu componente (x1, x2, ..., xN), care sunt valorile caracteristicilor acestui obiect.
OBJECT->Nfeatures->M-dimensional vector caracteristică
Clasă- idee neformalizabilă (de regulă) a posibilității de a atribui un obiect arbitrar din setul de obiecte ale sarcinii de recunoaștere unui anumit grup de obiecte. Pentru obiectele din aceeași clasă, se presupune prezența „asemănării”. Pentru problema recunoașterii modelelor, se poate defini un număr arbitrar de clase, mai mare decât 1. Numărul de clase este notat cu numărul S.
În general, problema recunoașterii modelelor constă din două părți: recunoaștere și învățare.
Recunoașterea modelelor este clasificarea unui anumit grup de obiecte pe baza anumitor cerințe. Obiectele care aparțin aceleiași clase de imagini au proprietăți comune. Cerințele care definesc clasificarea pot fi diferite, deoarece situațiile diferite necesită tipuri diferite de clasificări.
De exemplu, la recunoașterea literelor engleze, se formează 26 de clase de imagini. Cu toate acestea, pentru a distinge literele engleze de caracterele chinezești în timpul recunoașterii, sunt necesare doar două clase de imagini.
Cea mai simplă abordare a recunoașterii modelelor este potrivirea modelelor. În acest caz, un set de imagini, câte una din fiecare clasă de imagini, este stocat în memoria aparatului. Imaginea de intrare (recunoscută) (a unei clase necunoscute) este comparată cu standardul fiecărei clase. Clasificarea se bazează pe un criteriu de potrivire sau similaritate preselectat. Cu alte cuvinte, dacă imaginea de intrare se potrivește cu modelul clasei i-a de modele mai bine decât orice alt model, atunci modelul de intrare este clasificat ca aparținând clasei i-a de modele.
Dezavantajul acestei abordări, adică potrivirea cu un standard, este că în unele cazuri este dificil să alegeți un standard adecvat din fiecare clasă de imagini și să stabiliți criteriul de potrivire necesar.
O abordare mai avansată este aceea că clasificarea se bazează pe un set de măsurători selectate efectuate pe imaginile de intrare. Se presupune că aceste măsurători selectate, numite „caracteristici”, sunt invariante sau insensibile la schimbările și distorsiunile întâlnite frecvent și au o redundanță redusă.
Un caz special al celei de-a doua abordări de „măsurare a caracteristicilor”, în care standardele sunt stocate sub formă de caracteristici măsurate și un criteriu de clasificare special (comparație) este utilizat în clasificator.
Caracteristicile sunt definite de dezvoltatori și trebuie să fie invariante față de variațiile de orientare, dimensiune și formă ale obiectelor.
Prezentare generală a metodelor existente de recunoaștere a modelelor
L.P. Popova , ȘI DESPRE. Datiev
Abilitatea de a „;recunoaște”; Este considerată principala proprietate a ființelor umane, ca, într-adevăr, a altor organisme vii. Recunoașterea modelelor este o ramură a ciberneticii care dezvoltă principii și metode de clasificare și identificare a obiectelor, fenomenelor, proceselor, semnalelor, situațiilor - toate acele obiecte care pot fi descrise printr-un set finit de trăsături sau proprietăți care caracterizează un obiect.
O imagine este o descriere a unui obiect. Imaginile au o proprietate caracteristică, care se manifestă prin faptul că cunoașterea unui număr finit de fenomene din același set face posibilă recunoașterea unui număr arbitrar de mare a reprezentanților săi.
Există două direcții principale în teoria recunoașterii modelelor:
studiul puterilor de recunoaștere deținute de ființele umane și de alte organisme vii;
dezvoltarea teoriei și metodelor de construire a dispozitivelor destinate rezolvării problemelor individuale de recunoaștere a modelelor în anumite domenii de aplicare.
În continuare, articolul descrie problemele, principiile și metodele de implementare a sistemelor de recunoaștere a modelelor legate de dezvoltarea celei de-a doua direcții. A doua parte a articolului discută metodele rețelelor neuronale de recunoaștere a modelelor, care pot fi atribuite primei direcții a teoriei recunoașterii modelelor.
Probleme de construire a sistemelor de recunoaștere a imaginilor
Sarcinile care apar în construcția sistemelor automate de recunoaștere a modelelor pot fi de obicei clasificate în mai multe domenii principale. Prima dintre ele este legată de reprezentarea datelor inițiale obținute ca rezultate ale măsurătorilor pentru obiectul de recunoscut. problema de sensibilitate. Fiecare valoare măsurată este o caracteristică a unei imagini sau a unui obiect. Să presupunem, de exemplu, că imaginile sunt caractere alfanumerice. În acest caz, o retină de măsurare poate fi utilizată cu succes în senzor, similar cu cel prezentat în Fig. elemente, atunci rezultatele măsurătorii pot fi reprezentate ca un vector de măsurare sau un vector de imagine ![]() ,
,
unde fiecare element xi ia, de exemplu, valoarea 1 dacă imaginea simbolului trece prin celula i-a a retinei, iar valoarea 0 în caz contrar.
Luați în considerare fig. 2(b). În acest caz, imaginile sunt funcții continue (de tipul semnalelor sonore) ale variabilei t. Dacă valorile funcției sunt măsurate în puncte discrete t1,t2, ..., tn, atunci vectorul imagine poate fi format luând x1= f(t1),x2=f(t2),... , xn = f(tn).

Figura 1. Măsurarea retinei
A doua problemă a recunoașterii modelului este legată de selecția caracteristicilor sau proprietăților din datele inițiale obținute și de reducerea dimensiunii vectorilor de model. Această problemă este adesea definită ca o problemă preprocesare și selecție de caracteristici.
Caracteristicile unei clase de imagini sunt proprietăți caracteristice comune tuturor imaginilor unei clase date. Trăsăturile care caracterizează diferențele dintre clasele individuale pot fi interpretate ca trăsături interclase. Caracteristicile intraclase comune tuturor claselor luate în considerare nu sunt incluse Informatii utile din punct de vedere al recunoașterii și poate să nu fie luate în considerare. Alegerea caracteristicilor este considerată una dintre sarcinile importante asociate cu construcția sistemelor de recunoaștere. Dacă rezultatele măsurătorilor fac posibilă obținerea unui set complet de caracteristici distinctive pentru toate clasele, recunoașterea și clasificarea efectivă a modelelor nu va cauza dificultăți deosebite. Recunoașterea automată ar fi apoi redusă la un simplu proces de potrivire sau proceduri precum căutări în tabel. În majoritatea problemelor practice de recunoaștere, totuși, determinarea unui set complet de caracteristici distinctive este extrem de dificilă, dacă nu imposibilă. Din datele originale, de obicei, este posibil să extragem unele dintre caracteristicile distinctive și să le folosiți pentru a simplifica procesul de recunoaștere automată a modelelor. În special, dimensiunea vectorilor de măsurare poate fi redusă folosind transformări care minimizează pierderea de informații.
A treia problemă asociată cu construcția sistemelor de recunoaștere a modelelor este găsirea procedurilor de decizie optime necesare identificării și clasificării. După ce datele colectate despre modelele care trebuie recunoscute sunt reprezentate prin puncte sau vectori de măsurători în spațiul modelului, lăsați mașina să descopere cărei clase de modele îi corespund aceste date. Fie ca mașina să fie proiectată pentru a distinge între clasele M, notate cu w1, w2, ... ..., wm. În acest caz, spațiul imaginii poate fi considerat a fi format din M regiuni, fiecare dintre acestea conținând puncte corespunzătoare imaginilor din aceeași clasă. În acest caz, problema recunoașterii poate fi considerată ca construirea limitelor regiunilor de decizie care separă M clase pe baza vectorilor de măsurare înregistrați. Fie definite aceste limite, de exemplu, prin funcțiile de decizie d1(х),d2(x),..., dm(х). Aceste funcții, numite și funcții discriminante, sunt funcții scalare și cu o singură valoare ale imaginii lui x. Dacă di (x) > dj (x), atunci imaginea lui x aparține clasei w1. Cu alte cuvinte, dacă i-al-lea decisiv funcția di(x) are cea mai mare valoare, atunci o ilustrare semnificativă a unei astfel de scheme de clasificare automată bazată pe implementarea procesului decizional este prezentată în Fig. 2 (pe schema „GR” - generatorul de funcții decisive).

Figura 2. Schema de clasificare automată.
Funcțiile de decizie pot fi obținute în mai multe moduri. În acele cazuri în care sunt disponibile informații complete a priori despre tiparele recunoscute, funcțiile de decizie pot fi determinate exact pe baza acestor informații. Dacă sunt disponibile doar informații calitative despre tipare, se pot face ipoteze rezonabile cu privire la forma funcțiilor de decizie. În acest din urmă caz, granițele regiunilor de decizie se pot abate semnificativ de la cele adevărate și, prin urmare, este necesar să se creeze un sistem capabil să ajungă la un rezultat satisfăcător printr-o serie de ajustări succesive.
Obiectele (imaginile) care urmează să fie recunoscute și clasificate folosind un sistem automat de recunoaștere a modelelor trebuie să aibă un set de caracteristici măsurabile. Când pentru un întreg grup de imagini rezultatele măsurătorilor corespunzătoare sunt similare, se consideră că aceste obiecte aparțin aceleiași clase. Scopul sistemului de recunoaștere a modelelor este de a determina, pe baza informațiilor colectate, o clasă de obiecte cu caracteristici similare cu cele măsurate pentru obiectele recognoscibile. Corectitudinea recunoașterii depinde de cantitatea de informații distinctive conținute în caracteristicile măsurate și de eficiența utilizării acestor informații.
Metode de bază pentru implementarea sistemelor de recunoaștere a modelelor
Recunoașterea modelelor este sarcina de a construi și aplica operații formale asupra reprezentărilor numerice sau simbolice ale obiectelor din lumea reală sau ideală, rezultatele ale căror soluții reflectă relațiile de echivalență dintre aceste obiecte. Relaţiile de echivalenţă exprimă apartenenţa obiectelor evaluate la unele clase, considerate ca unităţi semantice independente.
La construirea algoritmilor de recunoaștere, clasele de echivalență pot fi stabilite de un cercetător care își folosește propriile idei semnificative sau folosește informații suplimentare externe despre asemănarea și diferența dintre obiecte în contextul problemei care se rezolvă. Apoi se vorbește despre „discernirea cu profesorul”. Altfel, i.e. atunci când un sistem automatizat rezolvă o problemă de clasificare fără a implica informații externe de instruire, se vorbește de clasificare automată sau „recunoaștere nesupravegheată”. Majoritatea algoritmilor de recunoaștere a modelelor necesită implicarea unei puteri de calcul foarte semnificative, care poate fi asigurată doar de tehnologia computerizată de înaltă performanță.
Diverși autori (Yu.L. Barabash, V.I. Vasiliev, A.L. Gorelik, V.A. Skripkin, R. Duda, P. Hart, L.T. Kuzin, F.I. Peregudov, F.P. Tarasenko, Temnikov F.E., Afonin V.A., Dmitriev V., Tu R., J. V. Gonzalez, P. Winston, K. Fu, Ya.Z. Tsypkin și alții) oferă o tipologie diferită a metodelor de recunoaștere a modelelor. Unii autori fac distincție între metodele parametrice, neparametrice și euristice, în timp ce alții evidențiază grupuri de metode bazate pe școli istorice și tendințe în acest domeniu.
În același timp, tipologiile cunoscute nu țin cont de o caracteristică foarte semnificativă, care reflectă specificul modului în care sunt reprezentate cunoștințele despre domeniul subiectului folosind orice algoritm formal de recunoaștere a modelelor. D.A. Pospelov identifică două modalități principale de reprezentare a cunoștințelor:
Reprezentare intensională – sub forma unei diagrame a relațiilor dintre atribute (trăsături).
Reprezentarea extensivă – cu ajutorul unor fapte concrete (obiecte, exemple).
Trebuie remarcat faptul că existența acestor două grupe de metode de recunoaștere: cele care operează cu trăsături și cele care operează cu obiecte, este profund firească. Din acest punct de vedere, nici una dintre aceste metode, luate separat de cealaltă, nu face posibilă formarea unei reflectări adecvate a domeniului subiectului. Între aceste metode există o relație de complementaritate în sensul lui N. Bohr, prin urmare, sistemele de recunoaștere promițătoare ar trebui să asigure implementarea ambelor metode, și nu a oricăreia dintre ele.
Astfel, clasificarea metodelor de recunoaștere propusă de D.A.Pospelov se bazează pe legile fundamentale care stau la baza modului uman de cunoaștere în general, ceea ce îl plasează într-o poziție (privilegiată) cu totul aparte față de alte clasificări, care, pe acest fond, arată mai ușor și mai artificial.
Metode Intensionale
O trăsătură distinctivă a metodelor intensionale este aceea că ele utilizează caracteristici diferite ale caracteristicilor și relațiile lor ca elemente ale operațiunilor în construcția și aplicarea algoritmilor de recunoaștere a modelelor. Astfel de elemente pot fi valori individuale sau intervale de valori ale caracteristicilor, valori medii și variații, matrice de relații de caracteristici etc., asupra cărora sunt efectuate acțiuni, exprimate într-o formă analitică sau constructivă. În același timp, obiectele din aceste metode nu sunt considerate unități informaționale integrale, ci acționează ca indicatori pentru evaluarea interacțiunii și comportamentului atributelor lor.
Grupul de metode intensionale de recunoaștere a modelelor este extins, iar împărțirea sa în subclase este oarecum arbitrară:
– metode bazate pe estimări ale densităților de distribuție a valorilor caracteristicilor
– metode bazate pe ipoteze despre clasa funcţiilor de decizie
– metode logice
– metode lingvistice (structurale).
Metode bazate pe estimări ale densităților de distribuție a valorilor caracteristicilor. Aceste metode de recunoaștere a modelelor sunt împrumutate din teoria clasică a deciziilor statistice, în care obiectele de studiu sunt considerate ca realizări ale unei variabile aleatoare multidimensionale distribuite în spațiul caracteristic conform unor legi. Ele se bazează pe o schemă bayesiană de luare a deciziilor care face apel la probabilitățile a priori ale obiectelor aparținând unei anumite clase de recunoscut și la densitățile de distribuție condiționată a valorilor vectorului caracteristic. Aceste metode sunt reduse la determinarea raportului de probabilitate în diferite zone ale spațiului caracteristic multidimensional.
Grupul de metode bazat pe estimarea densităților de distribuție a valorilor caracteristicilor este direct legat de metodele de analiză discriminantă. Abordarea bayesiană a luării deciziilor este una dintre cele mai dezvoltate în statistica modernă, așa-numitele metode parametrice, pentru care expresia analitică a legii distribuției (în acest caz, legea normală) este considerată cunoscută și doar o mică parte. numărul de parametri (vectori medii și matrice de covarianță) trebuie estimat.
Acest grup include, de asemenea, o metodă pentru calcularea raportului de probabilitate pentru caracteristicile independente. Această metodă, cu excepția asumării independenței trăsăturilor (care nu este, practic, niciodată îndeplinită în realitate), nu implică cunoașterea formei funcționale a legii distribuției. Poate fi atribuită metodelor neparametrice.
Alte metode neparametrice, utilizate atunci când forma curbei densității distribuției este necunoscută și nu se pot face deloc presupuneri cu privire la natura acesteia, ocupă o poziție specială. Printre acestea se numără binecunoscuta metodă a histogramelor multidimensionale, metoda „k-vecini cei mai apropiați”, metoda distanței euclidiene, metoda funcțiilor potențiale etc., a căror generalizare este metoda numită „Estimări Parzen”. Aceste metode operează în mod formal cu obiectele ca structuri integrale, dar în funcție de tipul sarcinii de recunoaștere, ele pot acționa atât în ipostaze intensionale, cât și extensionale.
Metodele neparametrice analizează numărul relativ de obiecte care se încadrează în volumele multidimensionale date și utilizează diferite funcții de distanță între obiectele eșantionului de antrenament și obiectele recunoscute. Pentru caracteristicile cantitative, când numărul lor este mult mai mic decât dimensiunea eșantionului, operațiunile cu obiecte joacă un rol intermediar în estimarea densităților de distribuție locală a probabilităților condiționate, iar obiectele nu poartă încărcătura semantică a unităților informaționale independente. În același timp, atunci când numărul de trăsături este proporțional sau mai mare decât numărul de obiecte studiate, iar trăsăturile sunt de natură calitativă sau dihotomică, atunci nu se poate vorbi despre estimări locale ale densităților distribuției probabilității. În acest caz, obiectele din aceste metode neparametrice sunt considerate unități informaționale independente (fapte empirice holistice) și aceste metode dobândesc semnificația unor aprecieri ale asemănării și deosebirii obiectelor studiate.
Astfel, aceleași operații tehnologice ale metodelor neparametrice, în funcție de condițiile problemei, au sens fie estimări locale ale densităților de distribuție a probabilității a valorilor caracteristicilor, fie estimări ale asemănării și diferenței obiectelor.
În contextul reprezentării intenționale a cunoștințelor, prima latură a metodelor neparametrice este considerată aici, ca estimări ale densităților distribuției probabilităților. Mulți autori observă că metodele neparametrice, cum ar fi estimările Parzen, funcționează bine în practică. Principalele dificultăți în aplicarea acestor metode sunt necesitatea de a reține întregul eșantion de antrenament pentru a calcula estimări ale densităților locale de distribuție a probabilității și sensibilitatea ridicată la nereprezentativitatea eșantionului de antrenament.
Metode bazate pe ipoteze despre clasa funcțiilor de decizie.În acest grup de metode se consideră cunoscută forma generală a funcției de decizie și se dă calitatea funcțională a acesteia. Pe baza acestei funcționale, se caută cea mai bună aproximare a funcției de decizie pentru secvența de antrenament. Cele mai comune sunt reprezentările funcțiilor de decizie sub formă de polinoame liniare și neliniare generalizate. Calitatea funcțională a regulii de decizie este de obicei asociată cu eroarea de clasificare.
Principalul avantaj al metodelor bazate pe ipoteze despre clasa funcțiilor de decizie este claritatea formulării matematice a problemei de recunoaștere ca problemă de găsire a unui extremum. Soluția la această problemă este adesea obținută folosind un fel de algoritmi de gradient. Varietatea metodelor acestui grup este explicată prin gama largă de funcționale de calitate a regulilor de decizie și algoritmi de căutare extremum. O generalizare a algoritmilor considerați, care includ, în special, algoritmul lui Newton, algoritmii de tip perceptron etc., este metoda de aproximare stocastică. Spre deosebire de metodele de recunoaștere parametrică, succesul acestui grup de metode nu depinde atât de mult de nepotrivirea ideilor teoretice despre legile distribuției obiectelor în spațiul caracteristic cu realitatea empirică. Toate operațiunile sunt subordonate unui singur scop principal - găsirea extremumului calității funcționale a regulii de decizie. În același timp, rezultatele metodelor parametrice și luate în considerare pot fi similare. După cum se arată mai sus, metodele parametrice pentru cazul distribuțiilor normale ale obiectelor din diferite clase cu matrice de covarianță egală conduc la funcții de decizie liniare. De asemenea, observăm că algoritmii pentru selectarea caracteristicilor informative în modelele de diagnostic liniare pot fi interpretați ca variante particulare ale algoritmilor de gradient pentru căutarea unui extrem.
Au fost studiate destul de bine posibilitățile algoritmilor de gradient pentru găsirea unui extremum, în special în grupul regulilor de decizie liniare. Convergența acestor algoritmi a fost dovedită doar în cazul în care clasele de obiecte recunoscute sunt afișate în spațiul caracteristic prin structuri geometrice compacte. Cu toate acestea, dorința de a obține o calitate suficientă a regulii de decizie poate fi adesea satisfăcută cu ajutorul algoritmilor care nu au o demonstrație matematică riguroasă a convergenței soluției la extremul global.
Astfel de algoritmi includ un grup mare de proceduri de programare euristică reprezentând direcția modelării evolutive. Modelarea evolutivă este o metodă bionică împrumutată din natură. Se bazează pe utilizarea unor mecanisme cunoscute de evoluție pentru a înlocui procesul de modelare semnificativă a unui obiect complex cu modelarea fenomenologică a evoluției acestuia.
Un reprezentant binecunoscut al modelării evolutive în recunoașterea modelelor este metoda de contabilizare de grup a argumentelor (MGUA). GMDH se bazează pe principiul auto-organizării, iar algoritmii GMDH reproduc schema selecției în masă. În algoritmii GMDH, membrii unui polinom generalizat sunt sintetizați și selectați într-un mod special, care este adesea numit polinomul Kolmogorov-Gabor. Această sinteză și selecție se realizează cu o complexitate crescândă și este imposibil de prezis în prealabil ce formă finală va avea polinomul generalizat. În primul rând, sunt de obicei considerate combinații simple perechi de trăsături inițiale, din care ecuațiile funcțiilor decisive sunt compuse, de regulă, nu mai mari decât ordinul doi. Fiecare ecuație este analizată ca o funcție de decizie independentă, iar valorile parametrilor ecuațiilor compuse se găsesc într-un fel sau altul din eșantionul de antrenament. Apoi, din setul rezultat de funcții de decizie, o parte din cele mai bune într-un anumit sens este selectată. Calitatea funcțiilor individuale de decizie este verificată pe un eșantion de control (test), care este uneori numit principiul adăugării externe. Funcțiile de decizie particulare selectate sunt considerate mai jos ca variabile intermediare care servesc drept argumente inițiale pentru o sinteză similară a noilor funcții de decizie etc. Procesul unei astfel de sinteze ierarhice continuă până la atingerea extremului criteriului de calitate a funcției de decizie, care în practică. se manifestă prin deteriorarea acestei calități atunci când se încearcă creșterea în continuare a ordinii membrilor polinomului în raport cu trăsăturile originale.
Principiul de auto-organizare care stă la baza GMDH se numește auto-organizare euristică, deoarece întregul proces se bazează pe introducerea de completări externe alese euristic. Rezultatul deciziei poate depinde în mod semnificativ de aceste euristici. Modelul de diagnostic rezultat depinde de modul în care obiectele sunt împărțite în eșantioane de antrenament și de testare, de modul în care este determinat criteriul de calitate a recunoașterii, de câte variabile sunt sărite în următorul rând de selecție etc.
Aceste caracteristici ale algoritmilor GMDH sunt, de asemenea, caracteristice altor abordări ale modelării evolutive. Dar remarcăm aici încă un aspect al metodelor luate în considerare. Aceasta este esența conținutului lor. Folosind metode bazate pe ipoteze despre clasa funcțiilor de decizie (evolutive și gradiente), este posibil să se construiască modele de diagnosticare de mare complexitate și să se obțină rezultate practic acceptabile. În același timp, atingerea scopurilor practice în acest caz nu este însoțită de extragerea de noi cunoștințe despre natura obiectelor recognoscibile. Posibilitatea extragerii acestor cunoștințe, în special cunoștințe despre mecanismele de interacțiune a atributelor (trăsăturilor), este limitată aici fundamental de structura dată a unei astfel de interacțiuni, fixată în forma aleasă a funcțiilor decisive. Prin urmare, maximul care se poate spune după construirea unui anumit model de diagnosticare este de a enumera combinațiile de caracteristici și caracteristicile în sine care sunt incluse în modelul rezultat. Dar sensul combinațiilor care reflectă natura și structura distribuțiilor obiectelor studiate rămâne adesea nedescoperit în cadrul acestei abordări.
Metode booleene. Metodele logice de recunoaștere a modelelor se bazează pe aparatul algebrei logice și permit operarea cu informații conținute nu numai în caracteristicile individuale, ci și în combinații de valori ale caracteristicilor. În aceste metode, valorile oricărui atribut sunt considerate evenimente elementare.
În cea mai generală formă, metodele logice pot fi caracterizate ca un fel de căutare a modelelor logice în eșantionul de antrenament și formarea unui anumit sistem de reguli de decizie logică (de exemplu, sub forma conjuncțiilor de evenimente elementare), fiecare dintre care are propria sa greutate. Grupul de metode logice este divers și include metode de complexitate și profunzime diferite de analiză. Pentru caracteristicile dihotomice (booleene), sunt populare așa-numitele clasificatoare de tip arbore, metoda de testare fără margini, algoritmul Kora și altele. Mai mult metode complexe se bazează pe formalizarea metodelor inductive ale lui D.S. Mill. Formalizarea se realizează prin construirea unei teorii cvasi-axiomatice și se bazează pe logica multi-sortată cu valori multiple cu cuantificatori pe tupluri de lungime variabilă.
Algoritmul Kora, ca și alte metode logice de recunoaștere a modelelor, este destul de laborios, deoarece este necesară o enumerare completă la selectarea conjuncțiilor. Prin urmare, atunci când se aplică metode logice, se impun cerințe ridicate privind organizarea eficientă a procesului de calcul, iar aceste metode funcționează bine cu dimensiuni relativ mici ale spațiului de caracteristici și numai pe computere puternice.
Metode lingvistice (sintactice sau structurale). Metodele lingvistice de recunoaștere a modelelor se bazează pe utilizarea unor gramatici speciale care generează limbaje, cu ajutorul cărora poate fi descris un set de proprietăți ale obiectelor recognoscibile. Gramatica se referă la regulile de construire a obiectelor din aceste elemente nederivate.
Dacă descrierea imaginilor se face cu ajutorul elementelor nederivate (subimagini) și a relațiilor lor, atunci se folosește o abordare lingvistică sau sintactică pentru a construi sisteme de recunoaștere automată folosind principiul comunității proprietăților. O imagine poate fi descrisă folosind o structură ierarhică de subimagini similară cu structura sintactică a unui limbaj. Această împrejurare face posibilă aplicarea teoriei limbajelor formale în rezolvarea problemelor de recunoaștere a modelelor. Se presupune că gramatica imaginilor conține seturi finite de elemente numite variabile, elemente nederivate și reguli de substituție. Natura regulilor de substituție determină tipul de gramatică. Printre cele mai studiate gramatici se numără gramaticile obișnuite, fără context și ale constituenților direcți. Punctele cheie ale acestei abordări sunt alegerea elementelor nederivate ale imaginii, unirea acestor elemente și relațiile care le unesc în gramatica imaginilor și, în cele din urmă, implementarea proceselor de analiză și recunoaștere în cadrul corespunzătoare. limba. Această abordare este utilă în special atunci când lucrați cu imagini care fie nu pot fi descrise prin măsurători numerice, fie sunt atât de complexe încât caracteristicile lor locale nu pot fi identificate și trebuie să faceți referire la proprietățile globale ale obiectelor.
De exemplu, E.A. Butakov, V.I. Ostrovsky, I.L. Fadeev propune următoarea structură de sistem pentru procesarea imaginii (Fig. 3), folosind o abordare lingvistică, în care fiecare dintre blocurile funcționale este un complex software (microprogram) (modul) care implementează funcțiile corespunzătoare.

Figura 3. Diagrama structurală a recunoașterii
Încercările de aplicare a metodelor lingvisticii matematice la problema analizei imaginii duc la necesitatea rezolvării unui număr de probleme legate de maparea unei structuri de imagine bidimensionale pe lanțuri unidimensionale ale unui limbaj formal.
Metode de extensie
În metodele acestui grup, spre deosebire de direcția intensională, fiecărui obiect studiat i se acordă o valoare diagnostică independentă într-o măsură mai mare sau mai mică. La baza lor, aceste metode sunt apropiate de abordarea clinică, care consideră oamenii nu ca un lanț de obiecte clasificate în funcție de unul sau altul indicator, ci ca sisteme integrale, fiecare dintre ele fiind individual și având o valoare diagnostică specială. O astfel de atitudine atentă față de obiectele de studiu nu permite excluderea sau pierderea informațiilor despre fiecare obiect individual, ceea ce apare atunci când se aplică metodele de direcție intențională, folosind obiecte doar pentru a detecta și fixa modelele de comportament ale atributelor lor.
Principalele operații în recunoașterea modelelor folosind metodele discutate sunt operațiunile de determinare a asemănării și diferenței obiectelor. Obiectele din grupul specificat de metode joacă rolul de precedente de diagnosticare. În același timp, în funcție de condițiile unei anumite sarcini, rolul unui precedent individual poate varia în limitele cele mai largi: de la participarea principală și definitorie la participarea foarte indirectă la procesul de recunoaștere. La rândul lor, condițiile problemei pot necesita participarea unui număr diferit de precedente de diagnosticare pentru o soluție de succes: de la unul în fiecare clasă de recunoscut până la dimensiunea completă a eșantionului, precum și căi diferite calculul măsurilor de asemănare și diferență a obiectelor. Aceste cerințe explică împărțirea ulterioară a metodelor extensiale în subclase:
metoda de comparare a prototipurilor;
metoda k-cel mai apropiat vecin;
echipe de reguli de decizie.
Metoda de comparare a prototipurilor. Aceasta este cea mai simplă metodă de recunoaștere extensivă. Este folosit, de exemplu, atunci când clasele recunoscute sunt afișate în spațiul de caracteristici în grupări geometrice compacte. În acest caz, centrul grupării geometrice a clasei (sau obiectul cel mai apropiat de centru) este de obicei ales ca punct prototip.
Pentru a clasifica un obiect necunoscut, se găsește prototipul cel mai apropiat de acesta, iar obiectul aparține aceleiași clase cu acest prototip. Evident, nu se formează imagini de clasă generalizate în această metodă.
Diferite tipuri de distanțe pot fi utilizate ca măsură a proximității. Adesea pentru caracteristicile dihotomice se folosește distanța Hamming, care în acest caz este egală cu pătratul distanței euclidiene. În acest caz, regula de decizie pentru clasificarea obiectelor este echivalentă cu o funcție de decizie liniară.
Acest fapt trebuie remarcat în mod deosebit. Demonstrează clar legătura dintre prototip și reprezentarea indicativă a informațiilor despre structura datelor. Folosind reprezentarea de mai sus, de exemplu, orice scară de măsurare tradițională, care este o funcție liniară a valorilor caracteristicilor dihotomice, poate fi considerată un prototip de diagnostic ipotetic. La rândul său, dacă analiza structurii spațiale a claselor recunoscute ne permite să concluzionam că acestea sunt compacte din punct de vedere geometric, atunci este suficient să înlocuim fiecare dintre aceste clase cu un prototip, care este de fapt echivalent cu un model de diagnostic liniar.
În practică, desigur, situația este adesea diferită de exemplul idealizat descris. Un cercetător care intenționează să aplice o metodă de recunoaștere bazată pe comparație cu prototipurile claselor de diagnostic se confruntă cu probleme dificile. Aceasta este, în primul rând, alegerea unei măsuri de proximitate (metrică), care poate schimba semnificativ configurația spațială a distribuției obiectelor. Și, în al doilea rând, o problemă independentă este analiza structurilor multidimensionale ale datelor experimentale. Ambele probleme sunt deosebit de acute pentru cercetător în condiții de dimensiune mare a spațiului caracteristic, ceea ce este tipic pentru problemele reale.
Metoda k-cei mai apropiati vecini. Metoda k-cel mai apropiat vecin pentru rezolvarea problemelor de analiză discriminantă a fost propusă pentru prima dată în 1952. Este după cum urmează.
Când se clasifică un obiect necunoscut, se găsește un număr dat (k) de alte obiecte care sunt cele mai apropiate din punct de vedere geometric de el în spațiul caracteristic (cei mai apropiati vecini) cu aparținând deja cunoscute la clase de recunoscut. Decizia de a atribui un obiect necunoscut unei anumite clase de diagnostic este luată prin analizarea informațiilor despre această apartenență cunoscută a vecinilor săi cei mai apropiați, de exemplu, folosind o simplă numărare a voturilor.
Inițial, metoda k-cel mai apropiat vecin a fost considerată o metodă neparametrică pentru estimarea raportului de probabilitate. Pentru această metodă se obțin estimări teoretice ale eficacității sale în comparație cu clasificatorul bayesian optim. Se dovedește că probabilitățile de eroare asimptotică pentru metoda k-cel mai apropiat vecin depășesc erorile regulii Bayes de cel mult două ori.
După cum sa menționat mai sus, în problemele reale este adesea necesar să se opereze cu obiecte care sunt descrise de un număr mare de caracteristici calitative (dihotomice). În același timp, dimensiunea spațiului caracteristic este proporțională sau depășește volumul eșantionului studiat. În astfel de condiții, este convenabil să se interpreteze fiecare obiect al eșantionului de antrenament ca un clasificator liniar separat. Apoi, una sau alta clasă de diagnosticare este reprezentată nu de un prototip, ci de un set de clasificatoare liniare. Interacțiunea combinată a clasificatorilor liniari are ca rezultat o suprafață liniară pe bucăți care separă clasele recunoscute în spațiul caracteristicilor. Tipul suprafeței divizoare, constând din bucăți de hiperplane, poate fi variat și depinde de poziția relativă a agregatelor clasificate.
O altă interpretare a mecanismelor de clasificare a k-cel mai apropiat vecin poate fi, de asemenea, utilizată. Se bazează pe ideea existenței unor variabile latente, abstracte sau legate prin vreo transformare cu spațiul caracteristic original. Dacă distanțele perechi dintre obiecte în spațiul variabilelor latente sunt aceleași ca în spațiul caracteristicilor inițiale, iar numărul acestor variabile este mult mai mic decât numărul de obiecte, atunci se poate lua în considerare interpretarea metodei k-nearest neighbors. din punctul de vedere al comparării estimărilor neparametrice ale densităților de distribuție de probabilitate condiționată. Conceptul de variabile latente prezentat aici este apropiat de conceptul de dimensionalitate adevărată și alte reprezentări utilizate în diferite metode de reducere a dimensionalității.
Când se utilizează metoda k-nearest neighbors pentru recunoașterea modelelor, cercetătorul trebuie să rezolve problema dificilă a alegerii unei metrici pentru a determina proximitatea obiectelor diagnosticate. Această problemă în condițiile dimensiunii mari a spațiului caracteristic devine extrem de agravată din cauza complexității suficiente a acestei metode, care devine semnificativă chiar și pentru calculatoarele performante. Prin urmare, aici, la fel ca în metoda comparației prototipului, este necesară rezolvarea problemei creative a analizei structurii multidimensionale a datelor experimentale pentru a minimiza numărul de obiecte reprezentând clase de diagnostic.
Algoritmi de calcul a notelor (votare). Principiul de funcționare al algoritmilor pentru calcularea scorurilor (ABO) este acela de a calcula prioritatea (scorurile de similaritate) care caracterizează „proximitatea” obiectelor recunoscute și de referință conform sistemului de ansambluri de caracteristici, care este un sistem de submulțimi ale unui dat. set de caracteristici.
Spre deosebire de toate metodele considerate anterior, algoritmii pentru calcularea estimărilor operează cu descrieri de obiecte într-un mod fundamental nou. Pentru acești algoritmi, obiectele există simultan în subspații foarte diferite ale spațiului caracteristic. Clasa ABO aduce ideea utilizării caracteristicilor la concluzia sa logică: deoarece nu se știe întotdeauna care combinații de caracteristici sunt cele mai informative, în ABO gradul de similitudine al obiectelor se calculează comparând toate combinațiile posibile sau anumite combinații de caracteristici. incluse în descrierile obiectelor.
Echipe de reguli de decizie. Regula de decizie folosește o schemă de recunoaștere pe două niveluri. La primul nivel funcționează algoritmii de recunoaștere privat, ale căror rezultate sunt combinate la al doilea nivel în blocul de sinteză. Cele mai comune metode ale unei astfel de combinații se bazează pe alocarea domeniilor de competență ale unui anumit algoritm. Cea mai simplă modalitate de a găsi domenii de competență este împărțirea a priori a spațiului caracteristicilor pe baza considerațiilor profesionale ale unei anumite științe (de exemplu, stratificarea eșantionului în funcție de anumite caracteristici). Apoi, pentru fiecare dintre zonele selectate, se construiește propriul algoritm de recunoaștere. O altă metodă se bazează pe utilizarea analizei formale pentru a determina zonele locale ale spațiului caracteristic ca vecinătăți de obiecte recunoscute pentru care a fost dovedit succesul unui anumit algoritm de recunoaștere.
Cea mai generală abordare a construirii unui bloc de sinteză consideră indicatorii rezultați ai algoritmilor parțiali ca caracteristici inițiale pentru construirea unei noi reguli de decizie generalizate. În acest caz, pot fi utilizate toate metodele de mai sus de direcții intensionale și extensiale în recunoașterea modelelor. Eficienți pentru rezolvarea problemei creării unui set de reguli de decizie sunt algoritmii logici de tip „Kora” și algoritmii pentru calcularea estimărilor (ABO), care stau la baza așa-numitei abordări algebrice, care oferă cercetare și o descriere constructivă a algoritmi de recunoaștere, în cadrul cărora se încadrează toate tipurile existente de algoritmi.
Metode de rețele neuronale
Metodele rețelelor neuronale sunt metode bazate pe utilizarea diferitelor tipuri de rețele neuronale (NN). Principalele domenii de aplicare a diferitelor NN-uri pentru recunoașterea modelelor și a imaginii:
aplicație pentru extragerea caracteristicilor sau caracteristicilor cheie ale imaginilor date,
clasificarea imaginilor în sine sau a caracteristicilor deja extrase din acestea (în primul caz, extragerea caracteristicilor cheie are loc implicit în cadrul rețelei),
rezolvarea problemelor de optimizare.
Rețele neuronale multistrat. Arhitectura unei rețele neuronale multistrat (MNN) constă din straturi conectate secvențial, unde neuronul fiecărui strat este conectat cu toți neuronii stratului anterior cu intrările sale și cu ieșirile celui următor.
Cea mai simplă aplicație a unui NN cu un singur strat (numită memorie auto-asociativă) este antrenarea rețelei pentru a reconstrui imaginile de alimentare. Prin introducerea unei imagini de testare la intrare și calculând calitatea imaginii reconstruite, se poate estima cât de bine a recunoscut rețeaua imaginea de intrare. Proprietățile pozitive ale acestei metode sunt că rețeaua poate recupera imagini distorsionate și zgomotoase, dar nu este potrivită pentru scopuri mai serioase.
MNN este, de asemenea, utilizat pentru clasificarea directă a imaginilor - intrarea este fie imaginea însăși într-o anumită formă, fie un set de caracteristici cheie extrase anterior ale imaginii, la ieșire, neuronul cu activitate maximă indică apartenența la clasa recunoscută (Fig. . 4). Dacă această activitate este sub un anumit prag, atunci se consideră că imaginea transmisă nu aparține niciunei dintre clasele cunoscute. Procesul de învățare stabilește corespondența imaginilor de intrare cu apartenența la o anumită clasă. Aceasta se numește învățare supravegheată. Această abordare este bună pentru sarcinile de control al accesului pentru un grup mic de oameni. Această abordare oferă o comparație directă a imaginilor în sine de către rețea, dar odată cu creșterea numărului de cursuri, timpul de instruire și funcționarea în rețea crește exponențial. Prin urmare, pentru sarcini precum căutarea unei persoane similare într-o bază de date mare, necesită extragerea unui set compact de caracteristici cheie din care să căutați.
O abordare de clasificare folosind caracteristicile de frecvență ale întregii imagini este descrisă în . A fost utilizat un NS cu un singur strat bazat pe neuroni multivalori.
B arată utilizarea NN pentru clasificarea imaginilor, atunci când intrarea în rețea primește rezultatele descompunerii imaginii prin metoda componentelor principale.
În MNS clasic, conexiunile neuronale interstrat sunt complet conectate, iar imaginea este reprezentată ca un vector unidimensional, deși este bidimensional. Arhitectura rețelei neuronale convoluționale își propune să depășească aceste neajunsuri. A folosit câmpuri locale de receptor (care oferă conectivitate bidimensională locală a neuronilor), ponderi generale (oferind detectarea unor caracteristici oriunde în imagine) și organizare ierarhică cu subeșantionare spațială (subeșantionare spațială). NN convoluțional (CNN) oferă rezistență parțială la schimbările de scară, deplasări, rotații, distorsiuni.
MNS sunt, de asemenea, folosite pentru a detecta obiecte de un anumit tip. Pe lângă faptul că orice MNS instruit poate determina într-o oarecare măsură dacă imaginile aparțin claselor „proprii”, poate fi antrenat special pentru a detecta în mod fiabil anumite clase. În acest caz, clasele de ieșire vor fi clase care aparțin și nu aparțin tipului de imagine dat. A fost folosit un detector de rețea neuronală pentru a detecta imaginea feței din imaginea de intrare. Imaginea a fost scanată cu o fereastră de 20x20 pixeli, care a fost alimentată la intrarea rețelei, care decide dacă zona dată aparține clasei de fețe. Antrenamentul s-a făcut folosind atât exemple pozitive (diverse imagini cu fețe), cât și exemple negative (imagini care nu sunt fețe). Pentru a crește fiabilitatea detectării, s-a folosit o echipă de NN-uri antrenate cu greutăți inițiale diferite, în urma căreia NN-urile au greșit în diferite moduri, iar decizia finală s-a luat prin votul întregii echipe.

Figura 5. Componentele principale (fețe proprii) și descompunerea imaginii în componente principale
NN este, de asemenea, folosit pentru a extrage caracteristicile cheie ale imaginii, care sunt apoi utilizate pentru clasificarea ulterioară. În , este prezentată o metodă pentru implementarea rețelei neuronale a metodei de analiză a componentelor principale. Esența metodei de analiză a componentelor principale este de a obține coeficienții maxim decoreleți care caracterizează modelele de intrare. Acești coeficienți sunt numiți componente principale și sunt utilizați pentru compresia statistică a imaginii, în care un număr mic de coeficienți sunt utilizați pentru a reprezenta întreaga imagine. Un NN cu un strat ascuns care conține N neuroni (care este mult mai mic decât dimensiunea imaginii), antrenat prin metoda de retropropagare a erorii pentru a restabili imaginea de intrare la ieșire, formează coeficienții primelor N componente principale la ieșirea neuroni ascunși, care sunt utilizați pentru comparație. De obicei, se folosesc 10 până la 200 de componente principale. Pe măsură ce numărul componentelor crește, reprezentativitatea acestuia scade foarte mult și nu are sens să folosiți componente cu numere mari. Când se utilizează funcții de activare neliniară ale elementelor neuronale, este posibilă o descompunere neliniară în componente principale. Neliniaritatea vă permite să reflectați cu mai multă acuratețe variațiile datelor de intrare. Aplicând analiza componentelor principale la descompunerea imaginilor feței, obținem componentele principale, numite fețe proprii, care au și o proprietate utilă - există componente care reflectă în principal caracteristici esențiale ale feței precum genul, rasa, emoțiile. Când sunt restaurate, componentele au un aspect asemănător feței, primele reflectând cea mai generală formă a feței, cea din urmă reprezentând diverse diferențe minore între fețe (Fig. 5). Această metodă este bine aplicabilă pentru căutarea imaginilor cu fețe similare în baze de date mari. Se arată și posibilitatea reducerii în continuare a dimensiunii componentelor principale cu ajutorul NS. Evaluând calitatea reconstrucției imaginii de intrare, se poate determina foarte precis dacă aceasta aparține clasei de fețe.
Rețele neuronale de ordin înalt. Rețelele neuronale de ordin înalt (HNN) diferă de MNN prin faptul că au un singur strat, dar intrările neuronilor primesc, de asemenea, termeni de ordin înalt care sunt produsul a două sau mai multe componente ale vectorului de intrare. Astfel de rețele pot forma, de asemenea, suprafețe de divizare complexe.
Rețele neuronale Hopfield. Hopfield NN (HSH) este cu un singur strat și complet conectat (nu există conexiuni ale neuronilor la ei înșiși), ieșirile sale sunt conectate cu intrări. Spre deosebire de MNS, NSH este relaxant, adică. fiind setat la starea inițială, funcționează până când ajunge într-o stare stabilă, care va fi valoarea sa de ieșire. Pentru a căuta un minim global în legătură cu problemele de optimizare, se folosesc modificări stocastice ale NSH.
Utilizarea NSH ca memorie asociativă vă permite să restaurați cu acuratețe imaginile la care a fost antrenată rețeaua atunci când o imagine distorsionată este alimentată la intrare. În acest caz, rețeaua își va „aminti” imaginea cea mai apropiată (în sensul minimului local de energie) și, astfel, o va recunoaște. O astfel de funcționare poate fi gândită și ca o aplicare secvențială a memoriei auto-asociative descrise mai sus. Spre deosebire de memoria auto-asociativă, NSH va restaura imaginea perfect exact. Pentru a evita minimele de interferență și pentru a crește capacitatea rețelei, sunt utilizate diferite metode.
Rețele neuronale auto-organizate Kohonen. Rețelele neuronale auto-organizate (SNNC) Kohonen asigură ordonarea topologică a spațiului imaginii de intrare. Ele permit maparea continuă topologic a spațiului n-dimensional de intrare în spațiul m-dimensional de ieșire, mn. Imaginea de intrare este proiectată într-o anumită poziție din rețea, codificată ca poziție a nodului activat. Spre deosebire de majoritatea celorlalte metode de clasificare și grupare, ordonarea topologică a claselor păstrează similaritatea de ieșire în modelele de intrare, ceea ce este util în special atunci când se clasifică datele care au un număr mare de clase.
Cognitron. Cognitronul în arhitectura sa este similar cu structura cortexului vizual, are o organizare ierarhică multistrat, în care neuronii dintre straturi sunt conectați doar local. Antrenat prin învățare competitivă (fără profesor). Fiecare strat al creierului implementează diferite niveluri de generalizare; stratul de intrare este sensibil la modele simple, cum ar fi liniile, și orientarea lor în anumite zone ale zonei vizuale, în timp ce răspunsul altor straturi este mai complex, abstract și independent de poziția modelului. Funcții similare sunt implementate în cognitron prin modelarea organizării cortexului vizual.
Neocognitron este o dezvoltare ulterioară a ideii de cognitron și reflectă mai precis structura sistemului vizual, vă permite să recunoașteți imaginile indiferent de transformările, rotațiile, distorsiunile și schimbările de scară ale acestora.
Cognitron este un instrument puternic de recunoaștere a imaginii, cu toate acestea, necesită costuri de calcul mari, care sunt în prezent de neatins.
Metodele rețelei neuronale considerate oferă recunoaștere rapidă și fiabilă a imaginii, dar atunci când se folosesc aceste metode, apar probleme în recunoașterea obiectelor tridimensionale. Cu toate acestea, această abordare are multe avantaje.
Concluzie
În prezent, există un număr destul de mare de sisteme de recunoaștere automată a modelelor pentru diferite probleme aplicate.
Recunoașterea modelelor prin metode formale ca direcție științifică fundamentală este inepuizabilă.
Metodele matematice de prelucrare a imaginii au o mare varietate de aplicații: știință, tehnologie, medicină, sfera socială. În viitor, rolul recunoașterii modelelor în viața umană va crește și mai mult.
Metodele rețelelor neuronale oferă recunoaștere rapidă și fiabilă a imaginii. Această abordare are multe avantaje și este una dintre cele mai promițătoare.
Literatură
Prezentare generală a metodelor de identificare a persoanelor pe baza imaginilor feței, ținând cont de caracteristicile recunoașterii vizuale
Revizuire... recunoaştere de către o persoană de obiecte cu contrast redus, incl. persoane. Adus revizuire uzual metode ... Existaîntreaga linie metode ... cale, ca urmare a studiului, o platformă pentru dezvoltarea de metodărecunoaştere ...
Imeni Glazkova Valentina Vladimirovna CERCETAREA SI DEZVOLTAREA METODELOR DE CONSTRUCȚIE DE INSTRUMENTE SOFTWARE PENTRU CLASIFICAREA DOCUMENTELOR DE HIPERTEXT MULTI-TEME Specialitatea 05
Rezumat disertațiedocumente hipertext. Capitolul contine revizuireexistentmetode rezolvarea problemei luate în considerare, descrierea... prin tăierea celor mai puțin relevante clase // Matematică metoderecunoaştereimagini: a 13-a Conferință panrusă. Regiunea Leningrad...
Slide 0 Prezentare generală a sarcinilor bioinformaticii legate de analiza și prelucrarea textelor genetice
LecturaADN și secvențe de proteine. Revizuire sarcinile bioinformaticii ca sarcini ... semnalele necesită utilizarea de moderne metoderecunoaştereimagini, abordări statistice și ... cu densitate scăzută a genelor. Existent programele de predicție genetică nu...
D.V. Brilyuk, V.V. Starovoitov. Metode ale rețelelor neuronale de recunoaștere a imaginilor // /
Kuzin L.T. Fundamentele ciberneticii: Fundamentele modelelor cibernetice. T.2. - M.: Energie, 1979. - 584 p.
Peregudov F.I., Tarasenko F.P. Introducere în analiza de sistem: Tutorial. – M.: facultate, 1997. - 389s.
Temnikov F.E., Afonin V.A., Dmitriev V.I. Bazele teoretice ale tehnologiei informației. - M.: Energie, 1979. - 511s.
Tu J., Gonzalez R. Principiile recunoașterii modelelor. / Per. din engleza. - M.: Mir, 1978. - 410s.
Winston P. Inteligența artificială. / Per. din engleza. - M.: Mir, 1980. - 520s.
Fu K. Metode structurale în recunoașterea modelelor: Tradus din engleză. - M.: Mir, 1977. - 320s.
Tsypkin Ya.Z. Fundamentele teoriei informaționale a identificării. - M.: Nauka, 1984. - 520s.
Pospelov G.S. Inteligența artificială este baza unui nou tehnologia de informație. - M.: Nauka, 1988. - 280s.
Yu. Lifshits, Metode statistice de recunoaștere a modelelor ///modern/07modernnote.pdf
Bohr N. Fizica atomică și cunoașterea umană. / Traducere din engleză. - M.: Mir, 1961. - 151s.
Butakov E.A., Ostrovsky V.I., Fadeev I.L. Procesarea imaginilor pe un computer.1987.-236s.
Duda R., Hart P. Recunoașterea modelelor și analiza scenei. / Traducere din engleză. - M.: Mir, 1978. - 510s.
Ducele V.A. Psihodiagnostic computerizat. - Sankt Petersburg: Frăție, 1994. - 365 p.
Aizenberg I. N., Aizenberg N. N. și Krivosheev G. A. Neuroni binari universali și multivalori: algoritmi de învățare, aplicații pentru procesarea și recunoașterea imaginilor. Note de curs în Inteligența artificială - Învățare automată și extragerea datelor în recunoașterea modelelor, 1999, pp. 21-35.
Ranganath S. și Arun K. Recunoașterea feței folosind caracteristici de transformare și rețele neuronale. Pattern Recognition 1997, Vol. 30, pp. 1615-1622.
Golovko V.A. Neurointeligență: teorie și aplicații. Cartea 1. Organizarea și antrenamentul rețelelor neuronale cu direct și feedback - Brest: BPI, 1999, - 260s.
Vetter T. și Poggio T. Clasele de obiecte liniare și sinteza imaginii dintr-un singur exemplu de imagine. IEEE Transactions on Pattern Analysis and Machine Intelligence 1997, voi. 19, pp. 733-742.
Golovko V.A. Neurointeligență: teorie și aplicații. Cartea 2. Autoorganizarea, toleranța la erori și utilizarea rețelelor neuronale - Brest: BPI, 1999, - 228s.
Lawrence S., Giles C. L., Tsoi A. C. și Back A. D. Recunoașterea feței: O abordare a rețelei neuronale convoluționale. IEEE Transactions on Neural Networks, Special Issue on Neural Networks and Pattern Recognition, pp. 1-24.
Wasserman F. Tehnologia neurocalculatoarelor: Teorie și practică, 1992 - 184p.
Rowley H. A., Baluja S. și Kanade T. Neural Network-Based Face Detection. Tranzacții IEEE privind analiza modelelor și inteligența mașinilor 1998, voi. 20, pp. 23-37.
Valentin D., Abdi H., O „Toole A. J. și Cottrell G. W. Modele conecționiste de procesare a feței: un sondaj. ÎN: Pattern Recognition 1994, Vol. 27, pp. 1209-1230.
DocumentEi alcătuiesc algoritmi recunoaştereimagini. Metoderecunoaştereimagini După cum sa menționat mai sus... realitatea nu este exista„ecosisteme în general” și exista doar câteva... concluzii din acest detaliat revizuiremetoderecunoaştere am prezentat in...
Adnotare: Vrem să ajungem la o înțelegere a fenomenului gândirii, pornind de la sarcinile de comportament și percepție, adică din sarcinile pentru soluția cărora creierul a apărut și a evoluat. În prelegerile anterioare, am vorbit despre comportament. Acum să vedem ce dă sarcina percepției pentru înțelegerea fenomenului gândirii. Vom avea în vedere câteva principii ale percepției „inteligente”, concretizate prin exemplul rezolvării problemei citirii automate a caracterelor scrise de mână. Orientarea practică nu a condus, așa cum se întâmplă adesea, la simplificarea și emascularea problemei percepției. Dimpotrivă, pentru a obține o soluție viabilă a fost necesară introducerea unor componente „intelectuale” orientate spre recunoaștere „cu înțelegere”.
Recunoasterea formelor
Încă de la începutul dezvoltării ciberneticii, percepția mașinii a imaginilor a fost cel mai adesea aleasă pentru studiul și modelarea inteligenței și, în special, a unor componente atât de evidente ale gândirii precum construirea unui sistem de cunoștințe generalizate despre mediu și utilizarea acestor cunoștințe în procesul. luarea deciziilor. Percepția informațiilor vizuale părea a fi cea mai convenabilă pentru modelare și, în același timp, cea mai semnificativă practic.
A fost imediat clar că pt solutie completa Sarcinile percepției vizuale ale mașinii necesită recunoaștere „inteligentă” sau recunoaștere „cu înțelegere”. Adesea au încercat chiar să reducă gândirea la percepție, punând pur și simplu un semn de identitate între ei. În viitor, vom vedea că gândirea și percepția sunt indisolubil legate, dar acest lucru este departe de același lucru. Prin urmare, studiile despre percepția vie (în primul rând vizuală) sunt cu siguranță utile pentru înțelegerea procesului de gândire, dar problema în ansamblu este departe de a fi rezolvată. În același timp, orientarea practică a muncii în domeniul analizei automate a informațiilor vizuale și dorința de fezabilitate tehnică au dus la o transformare serioasă a problemei. S-a dovedit practic aproape forțat să simplifice luarea în considerare a procesului de percepție prin reducerea acestuia la o clasificare în funcție de caracteristicile obiectelor simple, considerate separat. Această direcție a devenit cunoscută ca Recunoasterea formelor".
Recunoasterea formelor spre directie" Inteligență artificială„(AI) de cele mai multe ori nu a fost atribuită, deoarece, spre deosebire de sarcinile AI, un aparat matematic bine dezvoltat a apărut în recunoașterea modelelor, iar pentru obiectele nu foarte complexe, s-a dovedit a fi posibil să se construiască sisteme de recunoaștere (clasificare) practic funcționale. Ca urmare, tradiționalul recunoasterea formelor, pe de o parte, nu rezolvă problema analizei automate a imaginilor complexe și, pe de altă parte, nu este un instrument serios pentru modelarea inteligenței. Să luăm în considerare problemele conexe mai detaliat.
Pentru orice recunoaștere sunt necesare standarde sau modele de clase de obiecte recunoscute. Clasificarea metodelor de recunoaștere este posibilă în funcție de tipurile de standarde utilizate sau, ceea ce este aproape la fel, după metoda de reprezentare a obiectelor la intrarea sistemului de recunoaștere. Majoritatea sistemelor de recunoaștere a imaginilor folosesc de obicei metode raster, caracteristici sau structuri.
Abordarea raster corespunde standardelor care sunt imagini sau un fel de preparate de imagine. În timpul recunoașterii, imaginea de intrare prezentată sub forma unui raster punctat este comparată punct la punct cu toate cele de referință și se determină cu care dintre standarde se potrivește mai bine imaginea, de exemplu, are mai multe puncte comune. Imaginile de intrare și de referință trebuie să aibă aceeași dimensiune și aceeași orientare. De exemplu, în așa-numitul multifont-OCR (recunoaștere de tipărire a textului cu mai multe fonturi), acest lucru se realizează prin construirea de standarde diferite nu numai pentru fonturi diferite, ci și pentru diferite dimensiuni de caractere (dimensiuni) în cadrul aceluiași font. Recunoașterea caracterelor scrise de mână în acest fel este imposibilă din cauza variabilității prea mari a formei, mărimii și orientării.
De asemenea, posibil utilizare caz recunoaștere raster cu aducerea imaginii de intrare la dimensiuni și orientare standard. În acest caz, recunoașterea caracterelor scrise de mână printr-o metodă raster devine posibilă după gruparea fiecărei clase recunoscute și crearea unui șablon raster separat pentru fiecare cluster.
În cazul general, obținerea invarianței în ceea ce privește dimensiunea, forma și orientarea obiectelor recunoscute de un raster este o problemă complexă și adesea de nerezolvat. O altă problemă apare din necesitatea de a extrage din imagine fragmentul acesteia legat de un obiect separat. Această problemă este comună tuturor metodelor clasice de recunoaștere a modelelor.
În majoritatea covârșitoare a sistemelor de recunoaștere și, în special, în sistemele de citire optică omnifont existente, metoda caracteristicilor este cea principală. Cu abordarea caracteristicilor, standardele sunt construite folosind caracteristicile identificate în imagine. Imaginea de la intrarea sistemului de recunoaștere este reprezentată de un vector caracteristic. Orice poate fi considerat semne - orice caracteristică a obiectelor recognoscibile. Caracteristicile trebuie să fie invariante față de variațiile de orientare, dimensiune și formă ale obiectelor. De asemenea, este de dorit ca vectorii caracteristici legați de diferite obiecte din aceeași clasă să aparțină unei regiuni compacte convexe a spațiului caracteristic. caracteristică spațiu trebuie să fie fix și la fel pentru toate obiectele de recunoscut. Alfabetul semnelor este gândit de dezvoltatorul sistemului. Calitatea recunoașterii depinde în mare măsură de cât de bine este inventat alfabetul caracteristic. Nu există o metodă generală pentru construirea automată a alfabetului caracteristic optim.
Recunoașterea constă în obținerea a priori a unui vector complet de trăsături pentru orice obiect individual recognoscibil selectat în imagine și abia apoi în determinarea căruia dintre standarde îi corespunde acest vector. Standardele sunt construite cel mai adesea ca obiecte statistice sau geometrice. În primul caz, învățarea poate consta, de exemplu, în obținerea unei matrice de frecvență a apariției fiecărei trăsături în fiecare clasă de obiecte, și recunoașterea în determinarea probabilităților ca vectorul caracteristic să aparțină fiecărui standard.
Cu abordarea geometrică, rezultatul învățării este cel mai adesea împărțirea spațiului de trăsături în regiuni corespunzătoare diferitelor clase de obiecte recognoscibile, iar recunoașterea constă în determinarea în care dintre aceste regiuni se încadrează vectorul de intrare al trăsăturilor corespunzătoare obiectului recognoscibil. Dificultăți în alocarea vectorului caracteristică de intrare oricărei zone pot apărea în cazul intersecției zonelor și, de asemenea, dacă zonele corespunzătoare claselor individuale de recunoaștere nu sunt convexe și sunt situate în spațiul caracteristicilor în așa fel încât clasa recognoscibilă să nu fie separate de alte clase printr-un hiperplan. Aceste probleme sunt cel mai adesea rezolvate euristic, de exemplu, prin calcularea și compararea distanțelor (nu neapărat euclidiene) în spațiul caracteristic de la obiectul de testare la centrele de greutate ale submulților eșantionului de antrenament corespunzătoare diferitelor clase. Sunt posibile și măsuri mai radicale, de exemplu, schimbarea alfabetului caracteristicilor sau gruparea eșantionului de antrenament sau ambele în același timp.
Abordarea structurală corespunde descrierilor de referință construite în termeni de părți structurale ale obiectelor și relații spațiale dintre acestea. Elementele structurale se disting, de regulă, pe conturul sau pe „scheletul” obiectului. Cel mai adesea, o descriere structurală poate fi reprezentată printr-un grafic care include elemente structurale și relațiile dintre ele. În timpul recunoașterii, este construită o descriere structurală a obiectului de intrare. Această descriere este comparată cu toate standardele structurale, de exemplu, se găsește un izomorfism al graficelor.
Metodele raster și structurale sunt uneori reduse la o abordare caracteristică, considerând în primul caz ca caracteristici punctele imaginii, iar în al doilea - elementele structurale și relațiile dintre ele. Observăm imediat că există o diferență fundamentală foarte importantă între aceste metode. Metoda raster are proprietatea de integritate. Metoda structurală poate avea integritate. Metoda atributelor nu are proprietatea de integritate.
Ce este integritatea și ce rol joacă ea în percepție?
clasic recunoasterea formelor organizate de obicei ca proces secvenţial, derulându-se „de jos în sus” (de la imagine la înțelegere) în absența controlului percepției de la nivelurile conceptuale superioare. Etapa de recunoaștere este precedată de etapa de obținere a unei descrieri a priori a imaginii de intrare. Operațiunile de extragere a elementelor din această descriere, de exemplu, trăsături sau elemente structurale, sunt efectuate local pe imagine, părți ale imaginii primesc o interpretare independentă, adică nu există o percepție holistică, care în cazul general poate duce la erori - un fragment de imagine considerat izolat poate fi adesea interpretat complet în funcție de - diferit în funcție de ipoteza percepției, adică de ce fel de obiect integral se presupune a fi văzut.
În al doilea rând, abordările tradiționale sunt axate pe recunoașterea (clasificarea) obiectelor considerate separat. Etapa recunoașterii efective ar trebui să fie precedată de etapa de segmentare (ruptură) a imaginii în părți corespunzătoare imaginilor obiectelor individuale recunoscute. De obicei se folosesc metode de segmentare a priori proprietăți specifice imaginea de intrare. Decizie generală nu există nicio sarcină de pre-segmentare. Cu excepția celor mai simple cazuri, criteriul de separare nu poate fi formulat în funcție de proprietățile locale ale imaginii în sine, adică înainte de a fi recunoscută.
Litere mici, chiar și textul scris de mână nu este cel mai dificil caz, dar pentru astfel de imagini, selectarea liniilor, cuvintelor și caracterelor individuale în cuvinte poate fi o problemă serioasă. Soluția practică la această problemă se bazează adesea pe enumerarea opțiunilor de segmentare, iar aceasta este complet diferită de ceea ce face creierul uman sau animal în procesul de percepție vizuală holistică direcționată către un scop. Să ne amintim ce a spus Sechenov: „Nu auzim și nu vedem, ci ascultăm și privim”. O astfel de percepție activă necesită reprezentări holistice ale obiectelor la toate nivelurile - de la părți individuale la scene complete - și interpretarea părților doar ca parte a întregului.
Astfel, dezavantajele majorității abordărilor tradiționale și, în primul rând, abordarea indicativă sunt lipsa de integritate a percepției, lipsa de intenție și organizarea unidirecțională consecventă a procesului „de jos în sus”, sau de la imagine la „ înţelegere".
Recunoașterea este posibilă și folosind rețelele neuronale de recunoaștere artificiale sau formale (RNN) învăluite într-o ceață aproape mistică. Uneori chiar sunt considerate ca un fel de analog al creierului. Recent, textele scriu pur și simplu „rețele neuronale”, omițând adjectivele „artificial” sau „formal”. De fapt, RNN este cel mai adesea doar un clasificator de caracteristici care construiește hiperplanuri separate în spațiul de caracteristici.
Neuronul formal utilizat în aceste rețele este un sumator cu un element de prag care calculează suma produselor valorilor caracteristicilor cu unii coeficienți, care nu sunt altceva decât coeficienții ecuației hiperplanului de separare în spațiul caracteristic. Dacă suma este mai mică decât pragul, atunci vectorul caracteristic este situat pe o parte a planului de separare, dacă mai mult - pe cealaltă. Asta e tot. Pe lângă construirea de hiperplane care separă și clasificarea după caracteristici, fără miracole.
Introducerea într-un neuron formal, în locul unui salt de prag de la -1 la 1, a unei tranziții lină (diferențiabilă), cel mai adesea asemănătoare sigma, nu schimbă nimic fundamental, ci permite doar utilizarea algoritmilor de învățare a rețelei de gradient, adică , găsirea coeficienților în ecuațiile planurilor de separare și efectuarea „pățuirii” limitelor de separare, atribuirea rezultatului recunoașterii, adică a muncii unui neuron formal în apropierea graniței, o estimare, de exemplu, în intervalul de la 0 la 1. Această estimare, într-o anumită măsură, poate reflecta „încrederea” sistemului în alocarea vectorului de intrare uneia sau alteia dintre zonele partajate ale spațiului caracteristic. În același timp, această estimare, strict vorbind, nu este nici o probabilitate, nici o distanță față de planul de separare.
O rețea de neuroni formali poate, de asemenea, aproxima suprafețele de separare neliniare cu planuri și, ca rezultat, poate combina regiuni neînrudite ale spațiului caracteristic. Acesta este ceea ce se întâmplă în rețelele multistrat.
În toate cazurile, o rețea neuronală formală de recunoaștere indicativă (PRNN) este un clasificator indicativ care construiește hiperplanuri separatoare și selectează zone într-un spațiu fix de caracteristici (caracteristici). PRNS nu poate rezolva alte probleme, iar PRNS rezolvă problema recunoașterii nu mai bine decât recunoaștetorii de caracteristici convenționale folosind metode analitice.
În plus, pe lângă recunoaștetorii de caracteristici, recunoaștetorii raster, inclusiv recunoaștetorii de ansamblu, pot fi construite pe neuroni formali. În acest caz, toate deficiențele notate ale dispozitivelor de recunoaștere raster sunt păstrate. Adevărat, pot exista unele avantaje, despre care vom vorbi în viitor.
Pentru a evita neînțelegerile, trebuie menționat că, în principiu, este posibil să se construiască un computer universal pe neuroni formali, folosind atât planuri de separare în spațiul variabilelor, cât și funcții logice ȘI, SAU și NU ușor de implementat pe neuronii formali, totuși. , nimeni nu construiește astfel de computere și discuții legate de Această problemă este în afara domeniului de aplicare a problemelor luate în considerare. Neurocalculatoarele sunt denumite de obicei fie pur și simplu recunoaștere neuronală, fie sisteme speciale, sarcini decisive, care sunt aproape de recunoașterea modelelor și folosesc de fapt recunoașterea bazată pe construcția de hiperplanuri separatoare în spațiul caracteristic sau pe baza unei comparații a unui raster cu o referință.
S-a remarcat deja mai sus că, pentru a modela gândirea, este foarte important, și poate chiar necesar, să înțelegem cum funcționează mecanismele neuronale ale unui creier viu. În acest sens, se pune întrebarea: sunt recunoașterea formală a rețelelor neuronale, dacă nu o soluție la problema modelării mecanismelor neuronale ale creierului, atunci măcar un pas important în această direcție? Din păcate, răspunsul trebuie să fie nu. Spre deosebire de o rețea neuronală activă, RIS este o caracteristică pasivă sau un clasificator raster cu toate dezavantajele clasificatoarelor tradiționale. Argumentele pe baza cărora se trage această concluzie vor fi analizate mai detaliat ulterior.
Așadar, sistemele tradiționale de recunoaștere, în primul rând orientative, bazate pe organizarea secvențială a procesului de recunoaștere și clasificare a obiectelor luate în considerare separat, nu pot rezolva în mod eficient problemele de percepție a informațiilor vizuale complexe, în principal din cauza lipsei de integritate și a scopului percepției. , lipsa de integritate în descrierile.(standardele) obiectelor recognoscibile și organizarea consecventă a procesului de recunoaștere. Din același motiv, astfel de sisteme de recunoaștere a modelelor nu fac nimic pentru a înțelege percepția vizuală vie și procesul de gândire.
Imaginea este înțeleasă ca o descriere structurată a obiectului sau fenomenului studiat, reprezentată de un vector de trăsături, fiecare element al căruia reprezintă valoarea numerică a uneia dintre trăsăturile care caracterizează obiectul corespunzător.
Structura generală sistemul de recunoaștere are următoarea formă:
Sensul problemei de recunoaștere este de a stabili dacă obiectele studiate au un set finit fix de caracteristici care le permit să fie atribuite unei anumite clase. Sarcinile de recunoaștere au următoarele trăsături caracteristice:
1. Acestea sunt sarcini de informare formate din două etape:
A. Aducerea datelor sursă într-o formă convenabilă pentru recunoaștere.
b. Recunoașterea în sine este un indiciu al apartenenței unui obiect la o anumită clasă.
2. În aceste probleme se poate introduce conceptul de analogie sau asemănare a obiectelor și se poate formula conceptul de proximitate a obiectelor ca bază pentru atribuirea obiectelor aceleiași clase sau clase diferite.
3. În aceste sarcini, se poate opera cu un set de precedente - exemple a căror clasificare este cunoscută și care, sub formă de descrieri formalizate, pot fi prezentate algoritmului de recunoaștere pentru a se ajusta la sarcina din procesul de învățare.
4. Pentru aceste probleme, este dificil să construiți teorii formale și să aplicați metode matematice clasice: adesea informații pentru o precizie model matematic sau câștigul din utilizarea modelului și a metodelor matematice nu este proporțional cu costurile.
5. În aceste sarcini, este posibilă „informația proastă” - informații cu lacune, eterogene, indirecte, neclare, ambigue, probabilistice.
Este recomandabil să distingem următoarele tipuri de sarcini de recunoaștere:
1. Sarcina de recunoaștere, adică atribuirea obiectului prezentat conform descrierii acestuia la una dintre clasele date (instruire cu profesor).
2. Sarcina clasificării automate este împărțirea unui set de obiecte (situații) în funcție de descrierile acestora într-un sistem de clase care nu se suprapun (taxonomie, analiză cluster, învățare nesupravegheată).
3. Problema alegerii unui set informativ de caracteristici în recunoaștere.
4. Problema reducerii datelor inițiale la o formă convenabilă pentru recunoaștere.
5. Recunoaștere dinamică și clasificare dinamică - sarcinile 1 și 2 pentru obiecte dinamice.
6. Sarcina de previziune - sarcinile 5, în care soluția trebuie să se refere la un moment oarecare din viitor.
Conceptul de imagine.
O imagine, o clasă este o grupare de clasificare în sistem care unește (identifică) un anumit grup de obiecte în funcție de un anumit atribut. Imaginile au o serie de proprietăți caracteristice, care se manifestă prin faptul că cunoașterea unui număr finit de fenomene din același set face posibilă recunoașterea unui număr arbitrar de mare a reprezentanților săi.
Ca imagine, se poate lua în considerare și un anumit set de stări ale obiectului de control, iar acest întreg set de stări se caracterizează prin faptul că același impact asupra obiectului este necesar pentru atingerea unui obiectiv dat. Imaginile au proprietăți obiective caracteristice, în sensul că diferiți oameni care învață din material de observație diferit, în cea mai mare parte, clasifică aceleași obiecte în același mod și independent unul de celălalt.
În general, problema recunoașterii modelelor constă din două părți: antrenament și recunoaștere.
Educația se realizează prin arătarea obiectelor individuale cu indicarea apartenenței lor la una sau la alta imagine. Ca rezultat al antrenamentului, sistemul de recunoaștere trebuie să dobândească capacitatea de a răspunde cu aceleași reacții la toate obiectele aceleiași imagini și reacții diferite la toate obiectele din imagini diferite.
Este foarte important ca procesul de învățare să se încheie doar prin afișarea unui număr finit de obiecte fără alte solicitări. Obiectele de învățare pot fi fie imagini vizuale, fie diverse fenomene ale lumii exterioare și altele.
Antrenamentul este urmat de procesul de recunoaștere a noilor obiecte, care caracterizează funcționarea unui sistem deja antrenat. Automatizarea acestor proceduri este problema antrenamentului în recunoașterea modelelor. În cazul în care o persoană însuși ghicește sau inventează și apoi impune computerului regulile de clasificare, problema recunoașterii este parțial rezolvată, deoarece partea principală și principală a problemei (antrenamentul) este preluată de persoană.
Problema pregătirii în recunoașterea modelelor este interesantă atât din punct de vedere aplicat, cât și din punct de vedere fundamental. Din punct de vedere aplicativ, rezolvarea acestei probleme este importantă, în primul rând, pentru că deschide posibilitatea automatizării multor procese care până acum au fost asociate doar cu activitatea unui creier viu. Semnificația fundamentală a problemei este legată de întrebarea ce poate și ce nu poate face un computer în principiu.
La rezolvarea problemelor de gestionare a metodelor de recunoaștere a modelelor, se folosește termenul „stare” în locul termenului „imagine”. Stare - anumite forme de afișare a caracteristicilor curente (instantanee) măsurate ale obiectului observat, setul de stări determină situația.
O situație este de obicei numită un anumit set de stări ale unui obiect complex, fiecare dintre acestea fiind caracterizată de aceleași caracteristici sau similare ale obiectului. De exemplu, dacă un obiect de control este considerat ca obiect de observație, atunci situația combină astfel de stări ale acestui obiect în care ar trebui aplicate aceleași acțiuni de control. Dacă obiectul de observație este un joc, atunci situația unește toate stările jocului.
Alegerea descrierii inițiale a obiectelor este una dintre sarcinile centrale ale problemei recunoașterii modelelor de învățare. Cu o alegere cu succes a descrierii inițiale (spațiul caracteristicilor), sarcina de recunoaștere se poate dovedi a fi banală. În schimb, o descriere inițială aleasă fără succes poate duce fie la o prelucrare ulterioară a informațiilor foarte dificilă, fie la nicio soluție.
Abordări geometrice și structurale.
Orice imagine care apare ca urmare a observării unui obiect în procesul de învățare sau examen poate fi reprezentată ca un vector și, prin urmare, ca un punct într-un spațiu caracteristic.
Dacă se afirmă că atunci când se afișează imagini este posibil să le atribuie fără ambiguitate uneia dintre două (sau mai multe) imagini, atunci se afirmă prin aceasta că într-un anumit spațiu există două sau mai multe regiuni care nu au puncte comune și că imaginea unui punct este din aceste regiuni. Fiecărui punct al unei astfel de zone i se poate atribui un nume, adică să dea un nume corespunzător imaginii.
Să interpretăm procesul de învățare a recunoașterii modelelor în termenii unei imagini geometrice, limitându-ne deocamdată la cazul recunoașterii doar a două modele. Singurul lucru cunoscut dinainte este că este necesar să se separe două regiuni într-un anumit spațiu și că sunt afișate doar punctele din aceste regiuni. Aceste zone în sine nu sunt predeterminate, adică nu există informații despre locația limitelor lor sau reguli pentru a determina dacă un punct aparține unei anumite zone.
În cursul instruirii, sunt prezentate punctele selectate aleatoriu din aceste zone și sunt raportate informații despre careia zonă aparțin punctele prezentate. Nu sunt raportate informații suplimentare despre aceste zone, adică locația limitelor lor în timpul antrenamentului.
Scopul învățării este fie de a construi o suprafață care să separe nu numai punctele afișate în procesul de învățare, ci și toate celelalte puncte aparținând acestor zone, fie de a construi suprafețe care să limiteze aceste zone astfel încât fiecare dintre ele să conțină doar puncte de aceeași imagine. Cu alte cuvinte, scopul învățării este de a construi astfel de funcții din vectori de imagine care ar fi, de exemplu, pozitive în toate punctele unei imagini și negative în toate punctele altei imagini.
Datorită faptului că regiunile nu au puncte comune, există întotdeauna un întreg set de astfel de funcții de separare, iar ca urmare a învățării, una dintre ele trebuie construită. Dacă imaginile prezentate aparțin nu a două, ci unui număr mai mare de imagini, atunci sarcina este de a construi, conform punctelor arătate în timpul antrenamentului, o suprafață care să separe toate zonele corespunzătoare acestor imagini unele de altele.
Această problemă poate fi rezolvată, de exemplu, prin construirea unei funcții care ia aceeași valoare peste punctele fiecărei regiuni, iar valoarea acestei funcții asupra punctelor din diferite regiuni ar trebui să fie diferită.
Poate părea că cunoașterea unui anumit număr de puncte din zonă nu este suficientă pentru a separa întreaga zonă. Într-adevăr, se poate specifica un număr nenumărat de regiuni diferite care conțin aceste puncte și, indiferent de modul în care este construită suprafața care selectează regiunea din ele, este întotdeauna posibil să se specifice o altă regiune care intersectează suprafața și, în același timp, conține punctele prezentate.
Cu toate acestea, se știe că problema aproximării unei funcții din informații despre aceasta într-un set limitat de puncte este mult mai restrânsă decât întreaga mulțime pe care este dată funcția și este o problemă matematică comună de aproximare a funcțiilor. Desigur, rezolvarea unor astfel de probleme necesită introducerea unor restricții asupra clasei de funcții luate în considerare, iar alegerea acestor restricții depinde de natura informațiilor pe care profesorul le poate adăuga procesului de învățare.
Un astfel de indiciu este conjectura despre compactitatea imaginilor.
Alături de interpretarea geometrică a problemei de a învăța să recunoască tipare, există o altă abordare, care se numește structurală sau lingvistică. Să luăm în considerare abordarea lingvistică pe exemplul recunoașterii vizuale a imaginilor.
În primul rând, se distinge un set de concepte inițiale - fragmente tipice găsite în imagine și caracteristici ale poziției relative a fragmentelor (stânga, jos, interior etc.). Aceste concepte inițiale formează un vocabular care vă permite să construiți diverse enunțuri logice, uneori numite propoziții.
Sarcina este de a selecta dintr-un număr mare de afirmații care ar putea fi construite folosind aceste concepte, cele mai semnificative pentru acest caz particular. În plus, privind un număr finit și, dacă este posibil, un număr mic de obiecte din fiecare imagine, este necesar să se construiască o descriere a acestor imagini.
Descrierile construite trebuie să fie atât de complete încât să rezolve problema cărei imagini îi aparține obiectul dat. La implementarea abordării lingvistice apar două sarcini: sarcina de a construi un dicționar inițial, adică un set de fragmente tipice, și sarcina de a construi reguli de descriere din elementele unui dicționar dat.
În cadrul interpretării lingvistice, se face o analogie între structura imaginilor și sintaxa unei limbi. Dorința pentru această analogie a fost cauzată de posibilitatea utilizării aparatului de lingvistică matematică, adică metodele sunt de natură sintactică. Utilizarea aparatului de lingvistică matematică pentru a descrie structura imaginilor poate fi aplicată numai după ce s-a realizat segmentarea imaginilor în părți componente, adică au fost dezvoltate cuvinte pentru a descrie fragmente tipice și metode de căutare a acestora.
După lucrările preliminare, care asigură selecția cuvintelor, apar sarcini lingvistice propriu-zise, constând în sarcini de analiză gramaticală automată a descrierilor pentru recunoașterea imaginilor.
ipoteza compactității.
Dacă presupunem că în procesul de învățare, spațiul caracteristic este format pe baza clasificării planificate, atunci putem spera că specificarea spațiului caracteristic în sine stabilește o proprietate, sub influența căreia imaginile din acest spațiu sunt ușor separate. Aceste speranțe sunt cele care, pe măsură ce s-au dezvoltat lucrările în domeniul recunoașterii modelelor, au stimulat apariția ipotezei compactității, care afirmă că seturile compacte din spațiul caracteristicilor corespund tiparelor.
Printr-un set compact vom înțelege anumite aglomerări de puncte din spațiul imaginii, presupunând că există rarefacții care le separă între aceste aglomerări. Cu toate acestea, această ipoteză nu a fost întotdeauna confirmată experimental. Dar acele probleme în care ipoteza compactității a fost bine îndeplinită și-au găsit întotdeauna o soluție simplă, și invers, acele probleme pentru care ipoteza nu a fost confirmată fie au fost deloc rezolvate, fie au fost rezolvate cu mare dificultate și informații suplimentare.
Ipoteza compactității în sine a devenit un semn al posibilității de a rezolva în mod satisfăcător problemele de recunoaștere.
Formularea ipotezei compactității ne aduce aproape de conceptul de imagine abstractă. Dacă coordonatele spațiului sunt alese aleatoriu, atunci imaginile din acesta vor fi distribuite aleatoriu. Vor fi mai dense în unele părți ale spațiului decât în altele.
Să numim un spațiu ales aleatoriu o imagine abstractă. În acest spațiu abstract, aproape sigur vor exista seturi compacte de puncte. Prin urmare, în conformitate cu ipoteza compactității, mulțimea de obiecte cărora le corespund seturi compacte de puncte într-un spațiu abstract se numește de obicei imagini abstracte ale unui spațiu dat.
Antrenament și autoformare, adaptare și formare.
Dacă ar fi posibil să se observe o anumită proprietate universală care nu depinde nici de natura imaginilor, nici de imaginile lor, ci determină doar capacitatea de separabilitate, atunci împreună cu sarcina obișnuită de a preda recunoașterea folosind informații despre apartenența fiecăruia. obiect din secvența de antrenament la o imagine sau alta, se poate ar fi mai bine să punem o altă problemă de clasificare - așa-numita problemă a învățării fără profesor.
O sarcină de acest fel la nivel descriptiv poate fi formulată astfel: obiectele sunt prezentate sistemului simultan sau secvenţial fără nicio indicaţie a apartenenţei lor la imagini. Dispozitivul de intrare al sistemului mapează un set de obiecte pe un set de imagini și, folosind unele proprietăți de separabilitate a imaginii încorporate în el în prealabil, realizează o clasificare independentă a acestor obiecte.
După un astfel de proces de auto-învățare, sistemul ar trebui să dobândească capacitatea de a recunoaște nu numai obiectele deja familiare (obiecte din secvența de antrenament), ci și pe cele care nu au fost prezentate înainte. Procesul de auto-învățare a unui anumit sistem este un astfel de proces, în urma căruia acest sistem, fără ajutorul unui profesor, dobândește capacitatea de a dezvolta aceleași reacții la imagini ale obiectelor aceleiași imagini și reacții diferite la imagini ale diferitelor imagini.
Rolul profesorului în acest caz constă doar în a determina sistemul unei proprietăți obiective care este aceeași pentru toate imaginile și determină capacitatea de a împărți un set de obiecte în imagini.
Se pare că o astfel de proprietate obiectivă este proprietatea compactității imaginilor. Aranjament reciproc punctele din spațiul selectat conține deja informații despre modul de împărțire a setului de puncte. Aceste informații determină proprietatea de separare a modelelor, care este suficientă pentru auto-învățare a sistemului de recunoaștere a modelelor.
Majoritatea algoritmilor de auto-învățare cunoscuți sunt capabili să selecteze doar imagini abstracte, adică seturi compacte în spații date. Diferența dintre ele constă în formalizarea noțiunii de compactitate. Cu toate acestea, acest lucru nu reduce și, uneori, chiar crește valoarea algoritmilor de auto-învățare, deoarece adesea imaginile în sine nu sunt predeterminate de nimeni, iar sarcina este de a determina ce subseturi de imagini dintr-un spațiu dat sunt imagini.
Un exemplu de astfel de enunțare a problemei este cercetarea sociologică, când grupurile de oameni sunt evidențiate în funcție de un set de întrebări. În această înțelegere a problemei, algoritmii de auto-învățare generează informații necunoscute anterior despre existența într-un spațiu dat a unor imagini despre care nimeni nu avea idee înainte.
În plus, rezultatul autoînvățării caracterizează adecvarea spațiului ales pentru o sarcină specifică de învățare prin recunoaștere. Daca imaginile abstracte alocate in spatiul autoinvatarii coincid cu cele reale, atunci spatiul a fost ales cu succes. Cu cât imaginile abstracte diferă de cele reale, cu atât mai incomod este spațiul ales pentru o anumită sarcină.
Învățarea este de obicei numită procesul de dezvoltare într-un sistem a unei anumite reacții la grupuri de semnale externe identice prin influențarea în mod repetat a sistemului de corecție extern. Mecanismul de generare a acestei ajustări determină aproape complet algoritmul de învățare.
Auto-învățarea diferă de învățare prin aceea că aici nu sunt raportate informații suplimentare despre corectitudinea reacției la sistem.
Adaptarea este procesul de modificare a parametrilor și structurii sistemului, și eventual a acțiunilor de control, pe baza informațiilor curente, pentru a atinge o anumită stare a sistemului cu incertitudine inițială și condiții de funcționare în schimbare.
Învățarea este un proces, în urma căruia sistemul dobândește treptat capacitatea de a răspunde cu reacțiile necesare la anumite seturi de influențe externe, iar adaptarea este ajustarea parametrilor și structurii sistemului pentru a atinge calitatea necesară a controlul în condițiile schimbărilor continue ale condițiilor externe.
Sisteme de recunoaștere a vorbirii.
Vorbirea acționează ca mijloc principal de comunicare între oameni și, prin urmare, comunicarea prin vorbire este considerată una dintre cele mai importante componente ale sistemului de inteligență artificială. Recunoașterea vorbirii este procesul de conversie a unui semnal acustic generat la ieșirea unui microfon sau a unui telefon într-o secvență de cuvinte.
O sarcină mai dificilă este sarcina de a înțelege vorbirea, care este asociată cu identificarea semnificației semnalului acustic. În acest caz, ieșirea subsistemului de recunoaștere a vorbirii servește ca intrare a subsistemului de înțelegere a rostirii. Recunoașterea automată a vorbirii (sisteme APP) este una dintre domeniile tehnologiilor de procesare a limbajului natural.
Recunoașterea automată a vorbirii este utilizată în automatizarea introducerii de texte în computere, în formarea de interogări orale către baze de date sau sisteme de regăsire a informațiilor, în formarea comenzilor orale către diferite dispozitive inteligente.
Concepte de bază ale sistemelor de recunoaștere a vorbirii.
Sistemele de recunoaștere a vorbirii sunt caracterizate de mulți parametri.
Unul dintre parametrii principali este eroarea de recunoaștere a cuvintelor (ORF). Acest parametru este raportul dintre numărul de cuvinte nerecunoscute și numărul total de cuvinte rostite.
Alți parametri care caracterizează sistemele automate de recunoaștere a vorbirii sunt:
1) dimensiunea dicționarului,
2) modul de vorbire,
3) stilul de vorbire,
4) domeniul de subiect,
5) dependența de vorbitori,
6) nivelul de zgomot acustic,
7) calitatea canalului de intrare.
În funcție de dimensiunea dicționarului, sistemele APP sunt împărțite în trei grupuri:
Cu o dimensiune mică de dicționar (până la 100 de cuvinte),
Cu o dimensiune medie a dicționarului (de la 100 de cuvinte la câteva mii de cuvinte),
Cu o dimensiune mare de dicționar (mai mult de 10.000 de cuvinte).
Modul de vorbire caracterizează modul în care sunt pronunțate cuvintele și frazele. Există sisteme de recunoaștere a vorbirii continue și sisteme care permit recunoașterea doar a cuvintelor izolate ale vorbirii. Modul izolat de recunoaștere a cuvintelor necesită ca vorbitorul să facă o pauză scurtă între cuvinte.
În funcție de stilul de vorbire, sistemele APP sunt împărțite în două grupe: sisteme de vorbire deterministe și sisteme de vorbire spontană.
În sistemele de recunoaștere a vorbirii deterministe, vorbitorul reproduce urmărirea vorbirii reguli gramaticale limba. Discursul spontan se caracterizează prin încălcări ale regulilor gramaticale și este mai greu de recunoscut.
În funcție de domeniu, există sisteme APP axate pe aplicarea în domenii foarte specializate (de exemplu, accesul la baze de date) și sisteme APP cu un domeniu de aplicare nelimitat. Acestea din urmă necesită o cantitate mare de vocabular și ar trebui să ofere recunoașterea vorbirii spontane.
Multe sisteme de recunoaștere automată a vorbirii depind de vorbitor. Aceasta implică reglarea prealabilă a sistemului la particularitățile pronunției unui anumit vorbitor.
Complexitatea rezolvării problemei recunoașterii vorbirii se explică prin variabilitatea ridicată a semnalelor acustice. Această variabilitate se datorează mai multor motive:
În primul rând, implementarea diferită a fonemelor - unitățile de bază ale sistemului de sunet al limbii. Variabilitatea implementării fonemelor este cauzată de influența sunetelor învecinate în fluxul de vorbire. Nuanțele realizării fonemelor, datorită mediului sonor, se numesc alofoni.
În al doilea rând, poziția și caracteristicile receptoarelor acustice.
În al treilea rând, modificări ale parametrilor vorbirii aceluiași vorbitor, care se datorează stării emoționale diferite a vorbitorului, ritmului vorbirii sale.
Figura prezintă principalele componente ale sistemului de recunoaștere a vorbirii:
Semnalul de vorbire digitizat intră în unitatea de preprocesare, de unde sunt extrase caracteristicile necesare recunoașterii sunetului. Recunoașterea sunetului se face adesea folosind modele de rețele neuronale artificiale. Unitățile de sunet selectate sunt folosite în viitor pentru a căuta o secvență de cuvinte care se potrivește cel mai bine cu semnalul de intrare.
Căutarea unei secvențe de cuvinte se realizează folosind modele acustice, lexicale și lingvistice. Parametrii modelului sunt determinați din datele de antrenament pe baza algoritmilor de învățare respectivi.
Sinteza vorbirii prin text. Noțiuni de bază
În multe cazuri, crearea sistemelor de inteligență artificială cu elemente de comunicare ei necesită transmiterea de mesaje sub formă de vorbire. Figura arată schema structurala sistem inteligent de întrebări-răspuns cu interfață de vorbire:
Poza 1.
Luați o bucată de prelegeri de la Oleg
Luați în considerare trăsăturile abordării empirice pe exemplul recunoașterii părților de vorbire. Sarcina este de a atribui etichete cuvintelor propoziției: substantiv, verb, prepoziție, adjectiv și altele asemenea. În plus, este necesar să se definească unele trăsături suplimentare ale substantivelor și verbelor. De exemplu, pentru un substantiv este un număr, iar pentru un verb este o formă. Oficializăm sarcina.
Să reprezentăm propoziția ca o secvență de cuvinte: W=w1 w2…wn, unde wn sunt variabile aleatoare, fiecare dintre ele primește una dintre valorile posibile aparținând dicționarului de limbă. Secvența etichetelor atribuite cuvintelor unei propoziții poate fi reprezentată de secvența X=x1 x2 … xn, unde xn sunt variabile aleatoare ale căror valori sunt definite pe setul de etichete posibile.
Atunci problema recunoașterii unei părți a vorbirii este de a găsi cea mai probabilă secvență de etichete x1, x2, …, xn având în vedere succesiunea de cuvinte w1, w2, …, wn. Cu alte cuvinte, este necesar să găsim o astfel de secvență de etichete X*=x1 x2 … xn care să ofere probabilitatea condiționată maximă P(x1, x2, …, xn| w1 w2.. wn).
Să rescriem probabilitatea condiționată P(X| W) ca P(X| W)=P(X,W) / P(W). Deoarece este necesar să se găsească probabilitatea condiționată maximă P(X,W) pentru variabila X, obținem X*=arg x max P(X,W). Probabilitatea comună P(X,W) poate fi scrisă ca un produs al probabilităților condiționate: P(X,W)=produs peste u-1 la n din P(x i |x1,...,x i -1 , w1,..., w i -1 ) P(w i |x1,…,x i -1 , w1,…,w i -1). Căutarea directă a maximului acestei expresii este o sarcină dificilă, deoarece pentru valori mari ale lui n spațiul de căutare devine foarte mare. Prin urmare, probabilitățile care sunt scrise în acest produs sunt aproximate prin probabilități condiționate mai simple: P(x i |x i -1) P(w i |w i -1). În acest caz, se presupune că valoarea etichetei x i este asociată numai cu eticheta anterioară x i -1 și nu depinde de etichetele anterioare și că probabilitatea cuvântului w i este determinată doar de eticheta curentă x i . Aceste ipoteze sunt numite Markovian, iar teoria modelelor Markov este folosită pentru a rezolva problema. Luând în considerare ipotezele lui Markov, putem scrie:
X*= arg x1, …, xn max П i =1 n P(x i |x i -1) P(wi|wi-1)
Acolo unde probabilitățile condiționate sunt estimate pe un set de date de antrenament
Căutarea unei secvențe de etichete X* se realizează folosind algoritmul de programare dinamică Viterbi. Algoritmul Viterbi poate fi considerat o variantă a algoritmului de căutare a graficului de stare, unde vârfurile corespund etichetelor cuvintelor.
În mod caracteristic, pentru orice vârf curent, setul de etichete copil este întotdeauna același. Mai mult decât atât, pentru fiecare vârf copil, și seturile de vârfuri părinte coincid. Acest lucru se explică prin faptul că tranzițiile se fac pe graficul de stare, ținând cont de toate combinațiile posibile de etichete. Ipoteza lui Markov oferă o simplificare semnificativă a problemei recunoașterii părților de vorbire, menținând în același timp o precizie ridicată a atribuirii etichetelor cuvintelor.
Deci, cu 200 de etichete, precizia atribuirii este de aproximativ 97%. Pentru o lungă perioadă de timp, analiza imperială a fost efectuată folosind gramatici stocastice fără context. Cu toate acestea, au un dezavantaj semnificativ. Constă în faptul că aceleași probabilități pot fi atribuite diferitelor analize. Acest lucru se datorează faptului că probabilitatea de parsare este reprezentată ca un produs al probabilităților regulilor implicate în parsare. Dacă în timpul analizei se folosesc reguli diferite, caracterizate de aceleași probabilități, atunci aceasta dă naștere la problema indicată. Cele mai bune rezultate sunt date de o gramatică care ține cont de vocabularul limbii.
În acest caz, regulile includ informațiile lexicale necesare care furnizează valori de probabilitate diferite pentru aceeași regulă în medii lexicale diferite. Analiza imperială este mai în concordanță cu recunoașterea modelelor decât analiza tradițională în sensul său clasic.
Studiile comparative au arătat că acuratețea parsării imperiale a aplicațiilor de limbaj natural este mai mare decât cea a analizei tradiționale.